| Автор |
Сообщение |
|
|
Дата: 13 Мар 2021 13:34:35 · Поправил: killer258 (13 Мар 2021 14:39:33)
#
Cобственно,на выходе будут биты Логично. Но как из работающего dsd извлечь битовый поток?Заманчиво это конечно очень ,но он же не выводит наружу значения таких своих внутренних переменных,как эти самые дибиты.Можно конечно попытаться ломануть dsd ,но не уверен,что получится. Есть конечно и еще один окольный вариант- настроить приемник на управляющий канал , включить dsd, перехватить TGID и СН ,выводимые dsd в окно , которое у него называется "Channel Activity", и вывести их затем скажем на СОМ порт,а там бы я ужепринял и сравнивал tgid с требуемым, и в случае совпадения ставил другой приемник в указанный Channel и там другой dsd начал бы декодировать указанный речевой канал. Но как их извлечь нужные циферки из виндового окна, не очень себе представляю.вариант с фотоматрицей,приложенной к нужному участку монитора и последующее распознавание образов цифр выглядит еще более кривым,хотя наверное ,реализуемым.
|
|
|
Дата: 13 Мар 2021 15:34:02
#
|
Реклама
Google
|
|
|
|
Дата: 13 Мар 2021 16:39:55 · Поправил: killer258 (14 Мар 2021 10:44:50)
#
Я просто не в курсе, что вы умеете
я могу для микроконтроллеров писать низкоуровневые процедуры, например, мне раньше приходилось декодировать пакеты эфирного протокола радиотелефонов Senao и выводить интерпретированные результаты в UART и на ЖКИ, пытался также взяться за пакеты управления NMT-450, но не успел тогда с ними поработать, они исчезли из эфира и вопрос отпал сам собой, а для компов к сожалению могу писать программы лишь под MS-DOS на турбопаскале тех времён, когда обьектно-ориентированного проектирования ещё не было в ходу. Во всяком случае, декодировать POCSAG с дискриминатора после усилителя-формирователя и подачи с него на компаратор и далее на линию LPT порта, у меня в те времена получалось. (но там правда, было попроще, чем сейчас, потому что менялась только длительность между переходами через ноль в зависимости от числа подряд идущих нулей или единиц, но не амплитуда). А под винды я писать не могу (за исключением нескольких совсем простых упражнений на Дэльфи) .
Ну на сколько я понимаю, какие-то старые версии DSD открыты, скачать исходники и модифицировать их:
https://github.com/szechyjs/dsd
Исходники по ссылкам я посмотрел, мелкие функции написаны на С, в них мне более-менее что-то понятно, язык С я понимаю , но часть написана на С++, который я не изучал, поэтому далеко не всё понятно в целом, хотя я глубоко пока и не разбирался ещё, так только по-быстрому пробежался по тексту, а значит, в ближайшее время подправить и перекомпилировать исходники не в состоянии, пока не изучу С++ и не приобрету некоторый опыт компиляции проектов на нём. По той же самой причине я в данный момент не могу позаимствовать оттуда нужные мне алгоритмы в той части, где DSD из аналогового сигнала с дискриминатора распознаёт дибиты. Тем более что там ещё и общение со звуковой картой , о котором я тоже имею очень смутное представление. Пока что надо выяснить, как назывался использовавшийся в том проекте компилятор, скачать и установить его у себя и попробовать скомпилировать ихний проект хотя бы без проведения изменений в нем, просто для начала убедится , что не вылетит сообщений об ошибках или о том,что компилятору чего-нибудь из файлов не достаёт. Если всё откомпилируется без проблем, тогда можно будет пробовать отыскивать и модифицировать отдельные места.
Исходники я ещё на досуге почитаю более внимательно. Может, извлеку оттуда некоторые ньюансы декодирования.
А вот на микроконтроллере типа пика или атмеги, тут я мог бы написать что-то такое, оцифровывающее встроенным в мк АЦП мгновенные значения напряжения с дискриминатора в серединах символьных интервалов, если бы осциллограммы не были искорёженными настолько , что в некоторых местах затрудняешься различить, то ли это у них уровень +1 , то ли это +3. А было бы было всё ровненько два чётких уровня в плюс и два минус, то я бы дальше просто "снимал" бы дибиты исходя из уровней сигнала и побитно прогонял бы их через несколько регистров , на каждом сдвиге сравнивая значения этих регистров с паттерном FS, пока не обнаружилось бы совпадение, и с этого момента уже было бы ясно, где начнётся первый бит пакета. Дальше я бы пропускал всё ненужное мне , ожидая появления единичного блока TSBK, названного в описании стандарта как "GRP_V_CH_GRANT_UPDT", в этом блоке должен быть opcode = %00000, и в одном из его октетов будет находиться предоставляемый кому-то для работы канал, в другом будет находиться тот TGID, которому этот канал в данный момент и предоставляется. Далее TGID поочередно сравню со списком интересующих, и в случае совпадения с одним из них берём номер канала, переводим его частоту в посылку, понятную для приёмника PCR-1000, и по UART отправляем команду приёмнику, чтоб он встал на эту частоту. Декодирование речи сделает DSD, работающий с тем приёмником. Ну вот как-то так я представляю себе решение этой задачи в общих чертах, если бы удалось привести в божеский вид идущий с дискриминатора сигнал. . А частоту стробирования середин символьных интервалов все же придётся восстанавливать , ориентируясь на переходы сигнала через ноль там, где они есть. Но беда в том, что эти интервалы запросто могут измениться, если нулевая линия дискриминатора чуть поднимется или опустится ,или расстройка по приёму на один килогерц, и тогда какой-нибудь переход через ноль не достигнет её, и точка изгиба кривой будет висеть чуть выше или ниже линии нуля, и символ будет разгадан неверно |
|
|
Дата: 14 Мар 2021 11:21:10 · Поправил: killer258 (14 Мар 2021 12:35:36)
#
Тем не менее, читаю dsd_dibit.c и и похоже, что ничего такого сверхестественного dsd при определении дибита не делает:
// by center, umid and lmid (ориентируемся на центр, среднее положительное и на среднее отрицательное)
if (symbol > state->center) //(то есть, если выше нулевой линии)
{
if (symbol > state->umid)
{
dibit = 1; // +3 (то бишь, если выше среднего положительного, значит, это +3)
}
else
{
dibit = 0; // +1 (иначе это +1)
}
}
else //( а если ниже нулевой линии)
{
if (symbol < state->lmid)
{
dibit = 3; // -3 (если ниже среднего отрицательного, значит, это -3)
}
else
{
dibit = 2; // -1 (иначе это -1)
}
То есть, DSD поступает точно так же, как пока что визуально пытаюсь делать это и я - если положительный уровень выше среднего umid, то он принимает решение, что это +3, если ниже, то это +1 , и аналогично для отрицательных -3 и -1.
Будь у меня облагороженный сигнал, то и я бы таким способом опознал дибиты,но вот только на моих осциллограммах уровни lmid и umid найти невозможно, так как есть амплитуды со "спорными" уровнями, которые не отнести ни к тем, ни к этим.. А на экранчике осциллограммы dsd , там картинка близка к идеальной, но как они её приблизили к вполне читабельному качеству, не понятно пока.
Впрочем, в этом же файлике кое-что про эти уровни сравнения есть:
state->max = lsum / opts->msize;
state->center = ((state->max) + (state->min)) / 2;
state->umid = (((state->max) - state->center) * 5 / 8) + state->center;
state->lmid = (((state->min) - state->center) * 5 / 8) + state->center;
state->maxref = (int)((state->max) * 0.80F);
state->minref = (int)((state->min) * 0.80F);
// то есть вроде как бы центр вычисляется как как среднее между краями, а порог компарирования выставляют на уровне 5/8 от максимальной амплитуды в обоих полярностях
Может быть, фишка в том, что они сами уровни осциллограммы корректируют в процедуре
p25p1_heuristics.c , тогда средние уровни возможно, окажутся там, где более менее и должны находиться.
Там табличка коррекции приведена, но непонятен масштаб величин.Скорее всего, уровни сигнала с дискриминатора надо будет вначале нормировать в каких-то условных значениях. |
|
|
Дата: 14 Мар 2021 12:20:52
#
killer258
Ну как вы видите, происходит высчитывание центра сигнала state->center, а затем и порогов. Плюс, видно, что работа ведется не с семплами, а symbol'ами. То есть, семплами, взятыми в определенный момент. Смотрите еще getSymbol().
|
|
|
Дата: 14 Мар 2021 17:09:06 · Поправил: killer258 (15 Мар 2021 11:39:39)
#
Раскуриваю getSymbol().
Действительно, всё крутится вокруг переменных state->symbolCenter и state->jitter, но уловить смысл многочисленных вложенных один в другой if-ов пока не хватило терпения. И не нашёл , где до этого получают свои значения переменные state->symbolCenter ,opts->symboltiming и have_sync, фигурирующие в ряде if-ов.
Поскольку частота дискретизации звуковой карты тут используется вряд ли больше чем 48 кГц, а символы в Р25 идут со скоростью 4800 в секунду, то семплов на один символ явно не более десяти. Скорее всего ровно десять. И один из них искомый. Только идею его вычисления в DSD я пока так и не смог понять. Ведь в самом начале, когда только ещё ищется преамбула, никакие CRC , Рид-Соломон и Голей использовать еще невозможно для определения уровня ошибок при том или ином временнОм положении момента чтения символа, а это положение уже нужно знать, иначе даже преамбула не прочтётся правильно и останется неопознанной.
Но видно, что DSD тратит на подстройку некоторое время. Так например, если ему скормить запись, в которой оставлена всего пара сотен символов, начиная от начала передачи, DSD не выдаст никакой информации, хотя Sync (преамбула) занимает всего 24 символа, идущий следом за ней NAC -всего 6 символов, тем не менее DSD не напишет в этом случае ничего : ни Sync, ни NAC. То есть во время прохождения первой пары сотен символов она ещё не готова. Но по времени это запаздывание небольшое, несколько десятков миллисекунд.
Глядя на окно осциллоскопа DSD, удивляюсь тому, что даже когда с приёмника на DSD в паузах поступает шум пустого канала(без передачи в нём), он даже хаотичный шум на выходе дискриминатора ухитряется обработать так, что он становится очень псевдо похожим на демодулированные C4FM сигналы, ибо чётко видны импульсы с амплитудами именно четырёх уровней - двух в положительной области и двух в отрицательной :-)
|
|
|
Дата: 15 Мар 2021 11:37:59 · Поправил: killer258 (15 Мар 2021 12:04:03)
#
Логично предложить использование буфера в некоторое количество сэмплов, приходящих с аудиокарты, достаточное для того, чтоб туда гарантированно поместилась преамбула и что-нибудь ещё, и десять быстрых попыток поиска совпадения с паттерном при разных моментах считывания символа в пределах этого буфера , и если в одной из попыток рано или поздно будет обнаружено совпадение с паттерном (когда с карты пойдет преамбула), то видимо, считать эту фазу правильной и с ней продолжить декодирование всего остального. Впрочем, при поиске преамбулы я думаю, можно даже не бегать по буферу 10 раз, а стоять на месте, проверяя одни и те же фиксированные семпловые места, отстоящие друг от друга на 10 семплов, содержимое буфера же само движется нам навстречу с каждым семплом и однажды преамбула попадёт на правильные места считывания и будет опознана, и с этого момента синхронизацию можно будет считать удавшейся. Имхо.
Но вот только если частота семплирования карты не в точности кратна символьной частоте, то правильная позиция считывания символов со временем постепенно будет сползать по времени и начнутся ошибки.
И я ещё подозреваю, что совпадение паттерна с преамбулой скорее всего будет зафиксировано не в только в одной центральной , но и в нескольких соседних семпловых позициях. Вот наверное для этого и придётся выявлять тот семп, который центральный. Наверное, это и есть тот самый state->symbolCenter
|
|
|
Дата: 15 Мар 2021 12:51:54 · Поправил: killer258 (15 Мар 2021 17:48:24)
#
работа ведется не с семплами, а symbol'ами. То есть, семплами, взятыми в определенный момент.
Кажется, я теперь начал догадываться , как можно отловить этот "определённый момент". Правда, только для случая, если частота семплирования в целое число раз кратна частоте следования символов, например, ровно 48 кгц, то есть строго 10 семплов на каждый символ.
Короче, начинаем с любого семпла , фиксируем его и далее все идущие через каждые 10 семплов . Фиксируем таким способом 24 сэмпла (по количеству символов в синхропакете (FS), и интерпретируем каждый из них как тот или иной символ по правилу отнесения к одному из четырёх уровней . Неважно, что получится, и правильно или нет. Просто тупо выполним это сравнение , отнеся каждый семпл в зависимости от его сравнения с положительным и отрицательным порогами к +1,+3,-1, -3, и всё.
Получаем 24 каких-то символа. В общем случае абсолютно неверных. В образце FS их тоже 24 , и они нам хорошо известны : +3,+3,+3,+3,+3,-3,+3,+3,-3,-3,+3,+3,-3,-3,-3,-3,+3,-3,+3,-3,-3,-3,-3,-3.
Сравниваем наши 24 символа с 24-рьмя символами синхропакета попарно, то есть первый с первым, второй со вторым и тд. Заводим переменную "степени совпадения" Sovpad , вначале пусть Sovpad=0, затем если первый символ из наших 24-рёх совпадает с первым символом из эталона синхропакета, то тогда Sovpad++, eсли не совпадает, то ничего не прибавляем, и так в цикле со всеми двадцатью четырьмя.
В случае полного совпадения мы получим максимально достижимое значение Sovpad==24, в случае полного несовпадения будет ноль, в случае частичного совпадения будет что-то в диапазоне 1..23
Если идёт эфирный шум или не синхропакет, то Sovpad будет прыгать вблизи небольших значений, а с проходом синхропакета по мере сдвига сэмплов Sovpad будет вначале расти, достигая 24, потом возможно будет столько же на следующем сэмпле, потом будет уменьшаться. Там в исходнике упоминается распределение Гаусса, и похоже, что это как раз об б этом.
И тогда по этой кривой распределения мы и найдём тот сэмпл, который является серединой.
Как-то так, я полагаю, надо действовать для нахождения момента, в который надо брать сэмпл. Похоже, что DSD действует на этом этапе аналогичным образом. Только у них там ещё и джиттер каким-то образом учитывается.
|
|
|
Дата: 15 Мар 2021 13:51:47
#
Если идёт эфирный шум или не синхропакет, то Sovpad будет прыгать вблизи небольших значений, а с проходом синхропакета по мере сдвига сэмплов Sovpad будет вначале расти, достигая 24, потом возможно будет столько же на следующем сэмпле, потом будет уменьшаться.
В целом мыслите верно. Только надо не совпадения считать, а взаимную корреляцию семплов полученных из эфира, с образцом в памяти. То есть, загоняете в память идеальную преамбулу, и начинаете высчитывать корреляцию с ней поступающих семплов. В искомый момент времени, корреляция достигнет максимума. Она будет расти, достигнет максимума, а потом начнет падать. Момент максимума и надо считать нужным моментом.
|
|
|
Дата: 15 Мар 2021 14:13:26 · Поправил: killer258 (15 Мар 2021 14:30:38)
#
То есть, загоняете в память идеальную преамбулу,
идеальную преамбулу - имеется ввиду преамбулу того вида, который она приобретает на передающей стороне перед подачей на ЧМ модулятор после прохождения корректирующего фильтра предыскажений "приподнятый косинус"?
|
|
|
Дата: 15 Мар 2021 14:31:22
#
идеальную преамбулу - имеется ввиду преамбулу того вида, который она приобретает на передающей стороне перед подачей на ЧМ модулятор после прохождения корректирующего фильтра "приподнятый косинус"?
Да.
 |
|
|
Дата: 15 Мар 2021 14:33:01 · Поправил: killer258 (15 Мар 2021 19:28:20)
#
Да.
Узнаю знакомую картинку:-)
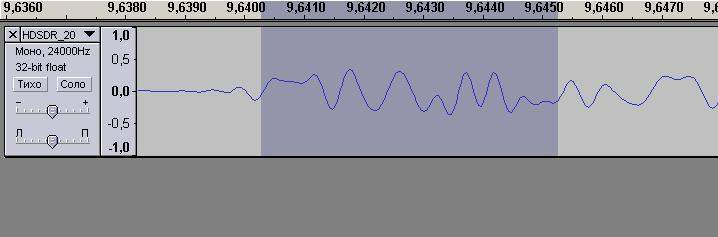
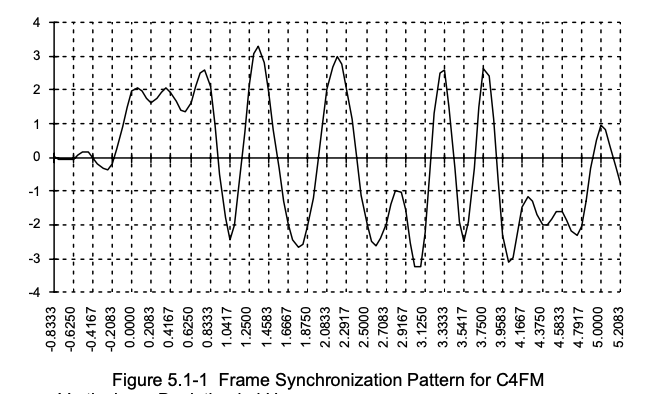
Значит, вот этот вот видимый и на моих осциллограммах тоже, начальный незначительный колебательный выброс на участке графика от -0.4167 до -0.2083 перед первыми пятью символами"+3", с которых начинается синхропакет, он действительно существует уже на передающей стороне, а не порождён "кривостью" моего приёмного ЧМ тракта или помехами, как я полагал. Я не знал, что с ним делать, ибо он всё время меня сбивал с толку, поскольку его вроде как быть в этом месте вообще не должно по описанию синхропакета, а он тут есть.. И по описанию синхропакета, в нём не содержится ни одного символа "+1" и "-1", а на графике можно подумать, что они есть на участке от 2.703 до 2.9167 . А оно вон как оказывается, что синхропакет именно так и выглядит, когда он с предыскажениями. А не так, как на регенерированной картинке. А я всё на свой приёмник грешил.
Я так полагаю, начало первого символа этого синхропакета находится не доходя пол-клетки до точки 0.0000, конец пакета не доходя пол-клетки до 5.0000, потому что именно в этом случае штрихпунктирные вертикальные линии на графике пересекают моменты правильного взятия значений, ибо видно визуально , что в эти моменты действительно нет ложных значений напряжения"+1" и "-1", которых в синхропакете Р25 никогда не содержится, ведь он состоит из одних только "+3" и "-3". И, кстати, я только что проверил,не поленился, все пересечения графикоа вертикальными пунктирными линиями соответствуют символам синхропакета : +3,+3,+3,+3,+3,-3,+3,+3,-3,-3,+3,+3,-3,-3,-3,-3,+3,-3,+3,-3,-3,-3,-3,-3.
Вот теперь и мне стало совершенно очевидно, что мой "визуальный" подход к поиску символов по осциллограмме , который я хотел алгоритмизировать, он не годится совершенно в принципе, а середины символов оказались вовсе не там, где я их искал , думая, что это верхушки импульсов. Нужно именно искать центры символов путём поиска максимальной корреляции синхропакета из эфира с его идеальным образцом , прописанным в памяти, только так и можно. Хорошая и познавательная штука всё-таки наш Радиосканнер, здесь можно получить подсказку и пофиксить пробелы знания в определённых областях.
Так это получается, что если забить в память точно таким же образом вычисленные образцы сэмплов всех 16 сочетаний двух соседних символов с учётом их влияния друг на друга, то после достижения синхронизации по преамбуле далее можно было бы тоже угадывать символы парами по максимальной коррелляции на символьном интервале с одним из 16 образцов возможных пар символов? Или этот способ не пройдёт и после синхронизации проще будет просто и тупо стробировать середины символьных интервалов с частотой следования символов и фиксировать там значения для выяснения, что это за дибиты?
И ещё остаётся нерассмотренным вопрос, как потом на ходу следить, не произошла ли со временем постепенная рассинхронизация последовательности моментов взятия уровня с центрами символьных интервалов . |
|
|
Дата: 15 Мар 2021 19:30:45
#
Или этот способ не пройдёт и после синхронизации проще будет просто и тупо стробировать середины символьных интервалов с частотой следования символов и фиксировать там значения для выяснения, что это за дибиты?
Ну извратиться так можно, только сложность вычислительная вряд ли порадует...
И ещё остаётся нерассмотренным вопрос, как потом на ходу следить, не произошла ли со временем постепенная рассинхронизация последовательности моментов взятия уровня с центрами символьных интервалов .
Точности кварцев должно хватать на хотя бы один пакет. Пересинхронизация должна выполняться при каждом новом пакете. Плюс, можно же подстраиваться в процессе приема по ошибке, как описано в документе выше.
|
|
|
Дата: 15 Мар 2021 22:26:42 · Поправил: killer258 (16 Мар 2021 16:28:24)
#
Я так и предполагал, что точности кварца по идее, должно будет хватить до окончания пакета.
Возник вопрос. Можно ли изображённый на графике двумя постами выше образец прошедшей через фильтр Найквиста идеальной преамбулы Р25 откуда-нибудь скачать в табличном виде с частотой следования сэмплов 48 кГц или эти значения можно получить только путём математических вычислений?
В принципе я могу написать для микроконтроллера простенькую прошивку, которая выдаст четырехуровневый сигнал этой преамбулы, и оцифровать его потом чем-нибудь, но вот беда, его ж вначале надо будет еще пропустить через уже упоминавшийся фильтр Найквиста с требуемой импульсной характеристикой, и я очень сомневаюсь в том,что могу его реализовать. Тем более что для точности получаемого образца преамбулы нужна будет полная идентичность тому фильтру, который реализован в передающих трактах тех станций. В самом крайнем случае можно наверное, табличку идеальной преамбулы составить и по приведённому выше графику, но будет ли достаточна точность? Всё-таки точные центры символов ищем, шаг вправо , шаг влево, и здравствуй межсимвольная интерференция. И хватит ли для семплирования разрядности 8 бит? (signed)
Имея такой табличный файлик, как я понял, уже можно будет для начала потренироваться на записях в их декодировании .
Хотя бы попробовать, используя его, "пройтись" по файлу какой-нибудь эфирной записи , полученной с дискриминатора с такой же самой частотой семплирования, и после нахождения максимальной корреляции с преамбулами пакетов и моментов считывания символов, разложить всю эту запись на дибиты .
А по дибитам кстати , можно без особого труда регенерировать запись, но только тогда регенерированные записи уже не будут нужны, раз и так всё будет декодироваться.
|
|
|
Дата: 17 Мар 2021 12:42:26 · Поправил: killer258 (18 Мар 2021 08:49:20)
#
Эврика!!
Я , кажется , наконец сообразил, как можно обзавестись этим самым массивом значений паттерна фреймовой синхронизации Р25 фазы1.
Берём приёмник (желательно наверное тот же самый, с которым будем декодировать и в дальнейшем тоже), по возможности находим сигнал P25 , идущий с ломовым уровнем, чтоб было максимально большое соотношение сигнал/шум в канале, делаем запись сигнала с дискриминатора с нужной частотой дискретизации. Не знаю пока, какой частоты будет достаточно, поэтому для начала пусть это будет 48 кгц.
Далее, я уже отмечал тремя постами выше, что благодаря представленному здесь участником Quasar_ru графику , синхропакет в записи очень легко узнаётся визуально (область на скриншоте выделена сиреневым цветом). Тем более что он находится в самом начале фрейма и перед ним всегда идёт горизонтальная линия, соответствующая немодулированной несущей (серия "NULL" битов). Поэтому просто берём аудиоредактор ,и удаляем из записи вообще всё кроме выбранного синхропакета, потом сохраняем.
Теперь мы имеем образец преамбулы, но он будет бесполезен без знания местоположения центров символов.
Но тут у меня на этот счёт тоже только что возникла идея. Поскольку про данный кусок мы на 100% знаем , что он является синхропакетом , а его содержимое нам абсолютно доподлинно известно из документов стандарта, то при правильном его чтении должно 100% получаться
"+3,+3,+3,+3,+3,-3,+3,+3,-3,-3,+3,+3,-3,-3,-3,-3,+3,-3,+3,-3,-3,-3,-3,-3" ( после обьединения дибитов это 0х5575F5FF77FF , 48 бит) ,
то можно один раз даже вручную не полениться и сделать ряд попыток взятия символов в различных позициях сьёма с интервалом следования 208.33 мксек (это заведомо известный нам период следования символов, ибо в Р25 идёт ровно 4800 символов в сек), и найти те позиции считывания, в которых без ошибок получается именно "+3,+3,+3,+3,+3,-3,+3,+3,-3,-3,+3,+3,-3,-3,-3,-3,+3,-3,+3,-3,-3,-3,-3,-3", а не что-нибудь другое.
Вот и всё, в результате станет известным, где находятся центры символов у образца. Заодно узнаем допустимую ошибку кадрирования, то есть на сколько отсчётов вправо и влево от "правильного" момента взятия символа можно отклониться без появления ошибок опознавания дибитов и какая минимальная частота дискретизации тут сгодится.
=================
PS: а ведь какой обманчиво простой казалась задача изначально.. Ну чего там такого, частотная модуляция четырьмя фиксированными уровнями, отклонение частоты несущей на 0.6 кГц уж никак невозможно спутать с отклонением частоты на 1.8 кГц, ведь различие уровней сигнала на выходе дискриминатора получается аж в три раза, казалось бы, ставь компараторы и не перепутаешь символы . А в действительности оказались весьма интересные ньюансы.
|
|
|
Дата: 18 Мар 2021 10:25:36
#
В принципе я могу написать для микроконтроллера простенькую прошивку, которая выдаст четырехуровневый сигнал этой преамбулы, и оцифровать его потом чем-нибудь, но вот беда, его ж вначале надо будет еще пропустить через уже упоминавшийся фильтр Найквиста с требуемой импульсной характеристикой, и я очень сомневаюсь в том,что могу его реализовать.
Тут матлаб в помощь. Надо генерировать синхропоследовательность, пропускать ее через RC фильтр с передискретизацией, повышая семпл рейт до любого, требуемого.
Берём приёмник
Это вариант попроще. Точность полученной таким образом преамбулы я думаю вполне достаточна для практической работы.
а ведь какой обманчиво простой казалась задача изначально..
Ну на фоне других видов модуляции типа QAM, Pi/4 QPSK да еще со всякими SC-FDMA, OFDM'ами задача действительно является легкой, но только для тех, кто уже имеет опыт.
|
|
|
Дата: 18 Мар 2021 12:32:06 · Поправил: killer258 (19 Мар 2021 09:12:45)
#
Во всяком случае, мне теперь стал наконец понятен физический смысл происходящего. При ограничении полосы у импульсов фронты затягиваются, и при слишком большой скорости смены символов эти "хвосты" не помещаются по времени в символьный интервал, но исчезнуть они не могут, им деваться некуда и поэтому они залезают во времени на следующий символьный интервал, и там прибавляются к значению отсчёта сигнала, поэтому осциллограмму так корёжит и это мешает детектированию, если оно производится не по центрам.
Полагаю, что если бы не шумы в канале, то можно было бы наверное в сигнале , идущем с дискриминатора, поднять уровень высокочастотных составляющих , пропустив через усилитель с корректирующей цепочкой , при этом хоть они и не восстановились бы полностью, но крутизна фронтов бы увеличилась, они бы меньше залезали на соседний интервал и интерференция наверное поуменьшилась бы, что уменьшило бы вероятность появления ошибок декодирования .
|
|
|
Дата: 22 Мар 2021 08:23:10 · Поправил: killer258 (23 Мар 2021 07:12:51)
#
Мне пришла идея, как можно упростить алгоритм поиска преамбулы, без вычисления корреляции с её операциями перемножения , которые занимают много времени у микроконтроллера, и сложения произведений.
Берём частоту семплирования в 10 раз выше символьной для Р25, то есть упомянутые 48 кГц. Берём кольцевой буфер, ёмкостью достаточной, чтоб в него поместилась преамбула при такой частоте семплирования. (так как в преамбуле 24 символа, то надо будет писать туда не менее 240 отсчётов. Ну, пусть для удобства работы с буфером его размер будет ровно 256 отсчётов).
С приходом каждого следующего семпла с ацп номер текущей ячейки записи буфера инкрементируется, затем в эту ячейку буфера пишется очередной отсчёт сигнала с дискриминатора (ну, или из файла), далее на этом шаге (на всё про всё у нас 20.8 мксек, тут надо будет прикинуть по времени выполнения, успеет ли атмега, или делать всё это на другом более быстром микроконтроллере) пробегаемся по всему остальному содержимому буфера , находим минимальное и максимальное, вычисляем середину и два порога сравнения, отрицательный и положительный. Затем в этой позиции буфера и ещё в двадцати трёх до неё, отстоящих друг от друга на 10 семплов, определяем символы. Далее попарно сравниваем на совпадение с теми 24 символами , из которых состоит преамбула по документу, то есть с
"+3,+3,+3,+3,+3,-3,+3,+3,-3,-3,+3,+3,-3,-3,-3,-3,+3,-3,+3,-3,-3,-3,-3,-3"
Поскольку с каждым семплом вся эта их последовательность сдвигается по буферу на 1/10 часть символьного интервала, то когда по буферу пойдёт преамбула с дискриминатора, то на каком-то шаге сдвига она неизбежно окажется своими центрами символов точно на тех позициях проверки, в которых проверяется на совпадение с образцом. С этого момента синхронизация у нас установлена, и дальше с этого сэмпла , вернее, с каждого десятого в дальнейшем, можно снимать дибиты. Или для верности сдвинуться вперёд ещё на один-два семпла, чтоб быть в центре символьного интервала, а не на самом его краю. (окно правильного декодирования я думаю, вполне можно будет определить опытным путём, я полагаю, что оно будет около 3-4 семплов. DSD насколько я понял, не ленится и определяет даже обе границы и центр правильного чтения символа)
Прохождение по буферу можно не прекращать, оставить его и дальше, так как на каждом шаге можно будет и дальше вычислять максимальное и минимальное значения в буфере и связанные с ними пороги сравнения, ведь уровень сигнала с дискриминатора в силу каких-либо причин может изменяться и мы это сможем своевременно учитывать при вычислении порогов. (и в случае нарастания ошибки кадрирования можно будет скорректировать момент взятия символа вперёд или назад на несколько семплов, но я пока не представляю детально, как это реализовать)
Дальше дибиты можно будет собирать в байты и писать куда-нибудь для последующего их анализа, чтоб понять, какого типа этот пакет и определить момент, где он закончился и понять, что дальше уже идёт эфирный шум и тогда провести необходимые операции с содержимым пакета (найти например, нужные TGID и CHANNEL в отведённых для этого полях пакетов канала управления, настроить другой приёмник на этот канал) и перейти в режим ожидания следующей преамбулы. Я так себе это представляю.
Если декодировать не в реальном времени с дискриминатора, а из файла и на компе, то тут будет имхо, попроще, так как и времени навалом и ресурсов у компа побольше, чем у микроконтроллера.
PS: Сейчас я посмотрел WAV файл, в котором HDSDR сохраняет запись сигнала с имеющегося в нём ЧМ демодулятора , он моно, 16-тибитный. Кстати, кто может подсказать,там в блоке семплов они идут вначале младший байт, а потом старший или наоборот?
И ещё возник вопрос. А не слишком ли это расточительно работать с 16 битными сэмплами для данной задачи? Может, тут и восьмибитного хватило бы для успешного различения символов?
|
|
|
Дата: 23 Мар 2021 22:14:08 · Поправил: killer258 (24 Мар 2021 08:18:48)
#
Поскольку пока нет ответа на последний вопрос, то решил пока попробовать поработать с 16-битной записью. Кстати, отсчёты в блоке данных wav файла идут сначала младший байт, потом старший.
Включил HDSDR, настроил на 450.200 (управляющий канал с очень хорошим здесь уровнем сигнала над шумом), на демодулированном сигнале поставил ограничение полосы в 3.8 кГц (хотя наверное, можно было бы сузить и до примерно 2.7 кГц), записал небольшой кусочек демодулированного сигнала в файл. Частота дискретизации 48 кГц, разрядность 16 бит, моно.
Потом набросал на Турбопаскале программку, которая прочла этот wav файл как типизированный файл и переписала его в массив значений типа integer, отбросив естественно заголовок wav файла. В этом формате звука значения могут быть в интервале от -32768 до +32767 , и тип integer как раз тоже в таком же диапазоне, что удобно.
Дальше программа нашла максимальное и минимальное значения в записи, перебрав все 11755 семплов. (взят не очень большой кусочек, 0.25 сек всего по времени, в нем несколько фреймов). Значения оказались :
+14068 наибольшее и
-13364 наименьшее.
То есть, уровень записи средний такой оказался, без перегрузки и в то же время не слишком маленький. И асимметрия в моём случае оказалась очень небольшой. Центр посчитал так же, как это делает DSD, получился центр равным
+352.
Далее программа посчитала пороги сравнения для положительной и отрицательной половин:
Refplus=5/8*(14068-352)+352=8924
Refminus= -5/8*(13364+352)+352=-8220
Не знаю, почему надо брать именно коэффициент 5/8 , но в DSD делают именно так (судя по тексту исходника), поэтому и я высчитываю так же.
Пороги сравнения известны, теперь завтра допишу еще немного программу, она сравнит все сэмплы с этими порогами и создаст другой, уже текстовый файл, в котором будут находиться уже не отсчёты, а условные "+1", "+3", "-1" или "-3", полученные в каждом сэмпле.
А потом надо будет добавить кусок программы, который пробежится по этому текстовому файлику и будет сравнивать
образец преамбулы, написанный в тех же +/-1 и +/-3, с разными сдвигами (десять вариантов, поскольку на один символьный интервал у меня приходится 10 отсчётов), и посмотрим, найдёт ли программа правильные места сьёма (центры символов), где без ошибок распознается заветный кусок "+3,+3,+3,+3,+3,-3,+3,+3,-3,-3,+3,+3,-3,-3,-3,-3,+3,-3,+3,-3,-3,-3,-3,-3"
Визуально-то я его и так вижу, в моём файле ближайшая преамбула находится от его начала на расстоянии примерно две с половиной сотни семплов, но надо, чтоб программа тоже "увидела".
(Всего в файлике 11755 семплов)
|
|
|
Дата: 24 Мар 2021 10:02:35
#
killer258
то на каком-то шаге сдвига она неизбежно окажется своими центрами символов точно на тех позициях проверки, в которых проверяется на совпадение с образцом. С этого момента синхронизация у нас установлена, и дальше с этого сэмпла , вернее, с каждого десятого в дальнейшем, можно снимать дибиты.
Ну это фактически тот же метод по оценке корреляции, только оценивается прореженная на 10 последовательность и ядро коррелятора бинарное (1/0 совпало/не совпало).
Работать будет, но только такой коррелятор может выдавать сигнал совпадения не только в правильный момент времени, а еще и +-1 семпл от него. Как порог настроите.
И асимметрия в моём случае оказалась очень небольшой.
Она плавать может в процессе работы. Постоянка на выходе дискриминатора это смещение между приемником и передатчиком по частоте.
|
|
|
Дата: 24 Мар 2021 10:45:07 · Поправил: killer258 (24 Мар 2021 10:51:41)
#
такой коррелятор может выдавать сигнал совпадения не только в правильный момент времени, а еще и +-1 семпл от него
А если допустим подсчитывать корреляцию так, как это было предложено ранее, то каким способом программа должна определять, что текущее значение корреляции и есть самое максимальное? Ведь помимо глобального максимума, как я полагаю, будет ещё и куча мелких локальных максимумов от случайных частичных совпадений . Я имею в виду не работу с файлом, где можно пройтись по нему вперёд и назад от текущей позиции, а обработку на лету в реальном времени, прямо с дискриминатора, когда неизвестно, каким будет следующий сэмпл.
Или нужно вначале тоже экспериментально установить какое-то пороговое значение корреляции, выше которого можно останавливать поиск и считать синхронизацию достаточной?
|
|
|
Дата: 24 Мар 2021 10:51:12
#
Ведь помимо глобального максимума, как я полагаю, будет ещё и куча мелких локальных
Ну естественно надо рассматривать только те значения корреляции, которые выше некоторого порога. Без порога никак.
Или нужно вначале тоже экспериментально установить какое-то пороговое значение корреляции, выше которого можно останавливать поиск и считать синхронизацию достаточной?
Не понял. Вы же максимум ищите. Максимум, который выше порога. Как нашли, значит засинхронизировались.
|
|
|
Дата: 24 Мар 2021 10:55:16 · Поправил: killer258 (24 Мар 2021 15:43:12)
#
Интересно, возможна ли ситуация ложной синхронизации, когда в блоке передаваемых данных случайно из соседних байтов сложится слово преамбулы ? или такое совпадение в протоколе Р25 предотвращено?
|
|
|
Дата: 24 Мар 2021 15:52:30
#
Интересно, возможна ли ситуация ложной синхронизации, когда в блоке передаваемых данных случайно из соседних байтов сложится слово преамбулы ? или такое совпадение в протоколе Р25 предотвращено?
Возможно конечно. Только вероятность этого мала. Ну и надо это учитывать при разработке софта.
|
|
|
Дата: 24 Мар 2021 21:41:39 · Поправил: killer258 (25 Мар 2021 21:29:28)
#
сегодня с помощью программы, которая пробежалась по wav файлу с отсчётами, я заменил значения отсчётов в файле на условные +/-1 и +/-3, потом пустил по этому файлу другую программу, которая должна была найти характерную для преамбулы последовательность значений, но она её не нашла :-(
Хотя когда я для проверки вписал в файл вручную сам в одном из мест нужные символы в нужном сочетании на правильных интервалах друг от друга, то программа совпадение находит, то есть тут всё правильно в этом месте. И что характерно, программа нашла мало символов, подпадающих под признак +3 и -3 (из которых и состоит преамбула), зато очень много отнесла в +1/3 и в -1/3
Я подозреваю, что наверное, пороги сравнения уровней неверно вычислил. Надо смотреть и разбираться.,
И ещё, если глядеть на график образца преамбулы, то там в конце преамбулы есть пара символов, уровень которых опасно приближается к половине амплитуды, можно сказать на грани дозволенного что вызывает сомнения в правильности порога 5/8. Наверное, уместнее всё же имхо понизить его ближе к 1/3. К сожалению, образец преамбулы не содержит ни одного символа +1/3 и -1/3, а только +3 и -3, поэтому судить по преамбуле о том, где надо провести границы сравнения, довольно сложно. Хотя, мне кажется, нужно поставить чуть-чуть выше 1/3, а не 5/8
|
|
|
Дата: 25 Мар 2021 09:56:09 · Поправил: killer258 (25 Мар 2021 21:23:49)
#
Было бы заманчиво позаимствовать ядро коррелятора из исходников DSD, но там я его так и не смог найти :-(
И по прежнему остаётся вопрос, можно ли вместо 16-битного формата сэмплов wav файла округлить его отсчёты до например 8 бит. Но думаю, что две последовательности, поделённые на одно и то же число, по идее, должны будут иметь ту же самую взаимную корреляцию
|
|
|
Дата: 25 Мар 2021 20:49:04 · Поправил: killer258 (26 Мар 2021 15:53:27)
#
Сейчас я переписал процедуру поиска совпадения преамбулы с образцом, исправив некоторые ошибки.
Теперь, когда я её запускаю по записи, в которой преамбула находится почти что в самом её начале, с каждым шагом сдвигаясь вперёд на один семпл (1/10 символьного интервала), преамбула на каком-то по счёту шаге обнаруживается :-)
Но при этом выяснились ньюансы. Совпадение всех 24 сэмплов с образцом преамбулы есть только на том шаге , на котором было обнаружено совпадение, и на следующем шаге тоже 100% совпадение . На ближайших к ним двух шагах, там уже появляется 1-2 ошибки. ещё шаг вперед или назад- там уже количество ошибок растёт резко - не менее 5-7 неверных символов из 24:
....
step=187: ... +1 +3 +3 +1 +3 -3 +1 +3 -3 -3 +1 +3 -3 -3 -1 -3 +3 -3 +3 -1 -3 -3 -3 -3 ... (совпад 75%)
step=188: ... +3 +3 +3 +3 +3 -3 +1 +3 -3 -3 +3 +3 -3 -3 -3 -3 +3 -3 +3 -1 -3 -3 -3 -3 ... (совпад 92%)
step=189: ... +3 +3 +3 +3 +3 -3 +3 +3 -3 -3 +3 +3 -3 -3 -3 -3 +3 -3 +3 -3 -3 -3 -3 -3 ... (совпад 100%)
step=190: ... +3 +3 +3 +3 +3 -3 +3 +3 -3 -3 +3 +3 -3 -3 -3 -3 +3 -3 +3 -3 -3 -3 -3 -3 ... (совпад 100%)
step=191: ... +3 +3 +3 +3 +3 -3 +3 +1 -3 -3 +3 +3 -3 -3 -3 -3 +3 -3 +3 -3 -1 -3 -3 -3 ... (совпад 92%)
step=192: ... +3 +3 +3 +3 +1 -3 +3 +1 -3 -3 +3 +1 -3 -3 -3 -1 +3 -3 +3 -3 -1 -3 -3 -3 ... (совпад 79%)
....
// шаг поиска=20.83 мксек, длительность символа=208.3 мксек,
шаг составляет 1/10 от времени символьного интервала, центр символов пришёлся на шаги с порядковым номером 189 и 190,
в которых взятие символов оказалось правильным. (Преамбула по документу должна иметь вид:
"+3,+3,+3,+3,+3,-3,+3,+3,-3,-3,+3,+3,-3,-3,-3,-3,+3,-3,+3,-3,-3,-3,-3,-3" )
Преамбула правильно прочлась на шагах 189 и 190. до и после в прочитанном уже появляются "+1" и "-1", которых в преамбуле по определению быть не может. И чем дальше от центра, тем ошибок больше.
Через 10 семплов после правильной позиции "взятия" снова возникает правильное чтение символов , также через 20, 30 и тд, как и ожидалось.
То есть , окно правильного детектирования составляет у меня всего два семпла . И это при скорости семплирования 48 кгц! Я ожидал большего, думал, что правильными будут +/-2 семпла в обе стороны от центра символа. Наверное, согласованная фильтрация после дискриминатора расширила бы окно. Тут правда, вспомнилось, что когда писал этот файл демод. сигнала , срез ачх демодулированного сигнала в HDSDR был выставлен где-то около 4 кгц. Надо будет попробовать записать тот же ссигнал с ограничением полосы до 2.8 кгц, и посмотреть, каким в этом случае станет окно детектирования, может, пошире станет. Хотя, кто знает, может быть, окно детектирования размером в 20% от длительности символьного интервала -это наверное и так вполне нормально?
И второй ньюанс (я вообще-то о нём подозревал, глядя на график образца преамбулы)
Безошибочное распознавание преамбулы происходит только при установке порогов сравнения в 1/3 от максимальных амплитуд. Если же выставляю порог 1/2 или 5/8, как в DSD, то уже начинаются сплошные ошибки, ни одного правильного распознавания преамбулы.
Надо теперь посидеть, подумать, "переварить" полученные результаты этих опытов с нахождением преамбулы.
Дальше за преамбулой по протоколу, насколько я помню, должен следовать NAC (16 бит), и поскольку он известен через DSD, то можно посмотреть, правильно ли он прочтётся здесь, потом надо посмотреть, что там дальше должно идти . Дальше вроде DataUnit ID 4 бита
|
|
|
Дата: 28 Мар 2021 12:05:09 · Поправил: killer258 (28 Мар 2021 15:26:43)
#
вернее, после FS (преамбула, 48 бит) должен следовать NID (64 бит) , в котором первые 12 бит - это будет NAC, cледующие 4 бита это Data Unit ID (DUID)которые , как я понял по документу , могут принимать только 5 возможных значений:
0000 - HDU
0011 - TDU (короткий терминатор без Link Control)
0101 - LDU1
1010 - LDU2
1100 - PDU (packet data unit)
1111 - TSDU (терминатор с Link Control информацией),
а далее идёт проверочный код BCH, всем этим можно будет воспользоваться для проверки .
следующие за преамбулой 8 символов в результате работы той же программы, что нашла FS, оказались следующими:
+3 -1 -3 +1 +1 -3 +3 -3
пробую перевести их в дибиты, в соответствии с тем, что
+3 --> это 01
+1 --> это 00
-1 --> это 01
-3 --> это 11
получилось
0110 1100 0011 и 01 11
то есть 0х6С3 , мало похожий на NAC, и DUID, не совпадающий ни с одним из 6 допустимых значений :-(
Похоже, что я слишком низко опустил планку разделения между +1 и +3, (а также соответственно между -1 и -3) и некоторые +1 ошибочно (как я предполагаю) были приняты за +3. (ещё, как вариант, может быть, надо всё-таки max и min вычислять не по всему файлу, а каждый раз в окрестностях текущего значения?)
Если предположить, что это действительно так, и в первом байте 0х0110 "01" на самом деле "00" (то есть не +3, а +1), второй байт считать правильно принятым(то есть "11" в нем была реально ниже уровня -1/3)
и в третьем байте 0х0011 "11" на самом деле "10" (то есть, не -3, а -1)
то тогда получается правдоподобное NAC=0х2С2
а в четырёх битах DUID 01 11 если следовать этому же предположению, то "01" может быть из-за заниженного уровня сравнения неправильно прочитанным "00" (то есть +1 тоже прочиталось как +3)
и тогда имеем 00 11 , и тогда это TDU (короткий терминатор без Link Control), что похоже на правду.
Последине 2 бита из этих четырёх (то есть 11, скорее всего твёрдое "-3") трудно заподозрить в том, что это не -3, а -1, так как в этом случае читалось бы не как 11, а как 10, а такие два последних бита DUID могут быть только в случае LDU1, но их здесь 100% не может быть, так как я декодирую траффик управляющего канала.
Короче, похоже, что надо сделать следующие поправки в алгоритм:
1 подкорректировать пороги сравнения
2 вычислять max и min на более узком интервале, вблизи текущего значения из файла
3 может быть, в демодулированом сигнале урезать полосу до 2880гц, как это делалось в передатчике перед модулятором фильтром "приподнятый косинус".
|
|
|
Дата: 28 Мар 2021 15:30:22
#
попробовал приподнять порог разделения между 1/3 и 1
NAC и DUID стали читаться как нужно, но зато в FS (преамбуле) появились неверные символы +1, которых там как известно, не должно быть, ибо там одни только +/-1 и +/-3 могут быть.
|
|
|
Дата: 28 Мар 2021 17:55:06 · Поправил: killer258 (29 Мар 2021 06:56:25)
#
Поэкспериментировал ещё немного с порогами сравнения уровней отсчётов аналогового сигнала, и я понял, что подбирать их непродуктивно, надо посмотреть общую картину.
А именно, надо пожалуй, собрать статистику, чтобы понять, с чем имею дело. Пройтись ещё раз по файлу, чтоб не только высчитать максимум с минимумом и смещение аналогового значения сигнала, но и построить график распределения значений в отсчётах. По идее, если сэмплы "взяты" в неправильны моменты времени, то в распределении значений будут присутствовать все значения от минимального до максимального, а по мере приближения к правильному моменту "взятия" они по идее, должны будут сгруппироваться вблизи четырёх максимумов и иметь в идеале низкую дисперсию, и соответственно, хвосты этих четырёх распределений не должны пересекаться. Реальнно же, судя по всему, они видимо пересекаются сейчас, и настолько, что невозможно проовести границы раздела для безошибочного различения символов.
Надо будет экспериментально определять для этих четырёх максимумов их математические ожидания и среднеквадратические отклонения, тогда вся картина станет видной, и можно будет подумать, что делать дальше. Мне так это представляется.
И я начинаю теперь подозревать, что помехоустойчивое кодирование BCH, Рида -Соломона и Голея , которое дальше там идёт, оно применено там неспроста :-)
Еще в DSD есть какой-то эвристический модуль, который учитывает влияние предыдущего символа на аналоговое значение символа текущего символа, возможно, это бы здесь помогло от неправильного чтения, но приведённая там таблица корректировок мне не внушает доверия или я что-то не так понял в ней, и кроме того там указано, что применять этот метод к символу можно только в том случае, если предыдущий однозначно был безошибочно определённым, а можно ли быть в этом уверенным.
|
Реклама
Google |
|




