| Автор |
Сообщение |
|
|
Дата: 29 Мар 2021 12:34:37 · Поправил: killer258 (30 Мар 2021 07:05:54)
#
исходник DSD приводит вот такую табличку
0 0: 3829.12 sd: 540.43 <-
0 1: 13352.45 sd: 659.74
0 2: -5238.56 sd: 1254.70
0 3: -13776.50 sd: 307.41
1 0: 3077.74 sd: 1059.00
11: 11935.11 sd: 776.20
1 2: -6079.46 sd: 1003.94
1 3: -13845.43 sd: 264.42
2 0: 5574.33 sd: 1414.71
2 1: 13687.75 sd: 727.68
2 2: -4753.38 sd: 765.95
2 3: -12342.17 sd: 1372.77
3 0: 6875.23 sd: 1837.38 <-
3 1: 14527.99 sd: 406.85
3 2: -3317.61 sd: 1089.02
3 3: -12576.08 sd: 1161.77
где первый столбец previous dibit, второй столбец current dibit
третий столбец - mean of the current dibit (аналоговое значение текущего дибита)
и четвёртый столбец с непонятным обьяснением "std deviation"
и пояснение перед таблицей:
In the C4FM P25 recorded files from the "samples" repository, it can be observed that there is a
correlation between the correct dibit associated for a given analog value and the value of the previous
dibit. For instance, in one P25 recording, the dibits "0" come with an average analog signal of
3829 when the previous dibit was also "0," but if the previous dibit was a "3" then the average
analog signal is 6875. These are the mean and std deviations for the full 4x4 combinations of previous and current dibits
По ихней таблице получается, что в зависимости от предыдущего символа уровень текущего символа "+1" и "-1" может изменяться аж чуть ли не в два раза. (кстати, с символами "+3" и "-3" такого сильного искажения не происходит, поэтому преамбулу распознать легче)
И для сочетания 3 0 результат 65875 выглядит ошибочным, там имхо предыдущий отрицательный уровень должен был утащить значение вниз отграницы раздела, а не вверх. Остальные сочетания выглядят достаточно правдоподобно.
Хотя с другой стороны, считается же вроде, что центры символьных интервалов не подвержены межсимвольной интерференции, зачем тогда эта таблица..
Но, вообще-то, судя по графику идеальной преамбулы, МСИ есть даже в центрах интервалов, просто в допустимых пределах. Например, двадцатый по счёту символ в преамбуле,который "-3", имеет уровень , довольно опасно приближающийся к уровню "-1", и будь он ещё хоть чуть-чуть выше, и уже прочлось бы как "-1"
а +/-1 значит, искажаются ещё больше и тоже опасно приближаются к линии раздела.
Получается, что даже правильный выбор момента взятия сэмпла всего лишь уменьшает МСИ, но даже там они всё равно не исчезают, просто они там минимальны.
Я ещё не смотрел максимумы на графиках распределения правильных сэмплов, но теперь догадываюсь, что даже в идеальном случае из-за МСИ они будут очень ощутимо размытыми и сильно приближаться к линии раздела ( особенно те, которые соответствуюют +/-1)
Итого, к чему я пришел, размышляя над вышеизложенным: я ожидаю распределение с 4 максимуми, а их ведь имхо, будет не 4.. И вот почему.
В случае отсутствия межсимвольных искажений симолы ложились бы по уровню строго на 4 горизонтальных линии +3,+1,-1, и -3, Как ноты на нотном стане.
А поскольку на аналоговый уровень символа влияет предыдущий (а им может быть любой из четырёх), то получается, что линейка возможных уровней символа расщепится на четыре. То же самое и с тремя оставшимися, у них тоже у каждого будет расщепление на четыре.
И таким образом, получается, что вместо четырёхуровневого сигнала мы реально имеем сигнал с 16 возможными уровнями, в которые чаще всего будут статистически попадать символы.
16 ожидаемых вероятностных значений плюс-минус некоторый разброс в обе стороны от каждого.
И четыре квантованных значения уровня у каждого символа ( в реальности 4 максимума наиболее вероятных значений)
Возможно, что на деле всё ещё сложнее, поскольку вроде бы говорилось где-то и про влияние последующего символа на текущий тоже. Тогда наверное, расщепление ещё больше, если это так.
|
|
|
Дата: 30 Мар 2021 20:52:09 · Поправил: killer258 (30 Мар 2021 20:55:54)
#
по той табличке выше, показывающей зависимость аналогового значения символа в зависимости от того, какой был предыдущий, все значения должны по идее группироваться вблизи шестнадцати уровней, у каждого символа будут 4 возможных уровня вместо одного, который был бы если б не было межсимвольной интерференции. Я примерно в масштабе нарисовал это распределение, получилось как-то так:
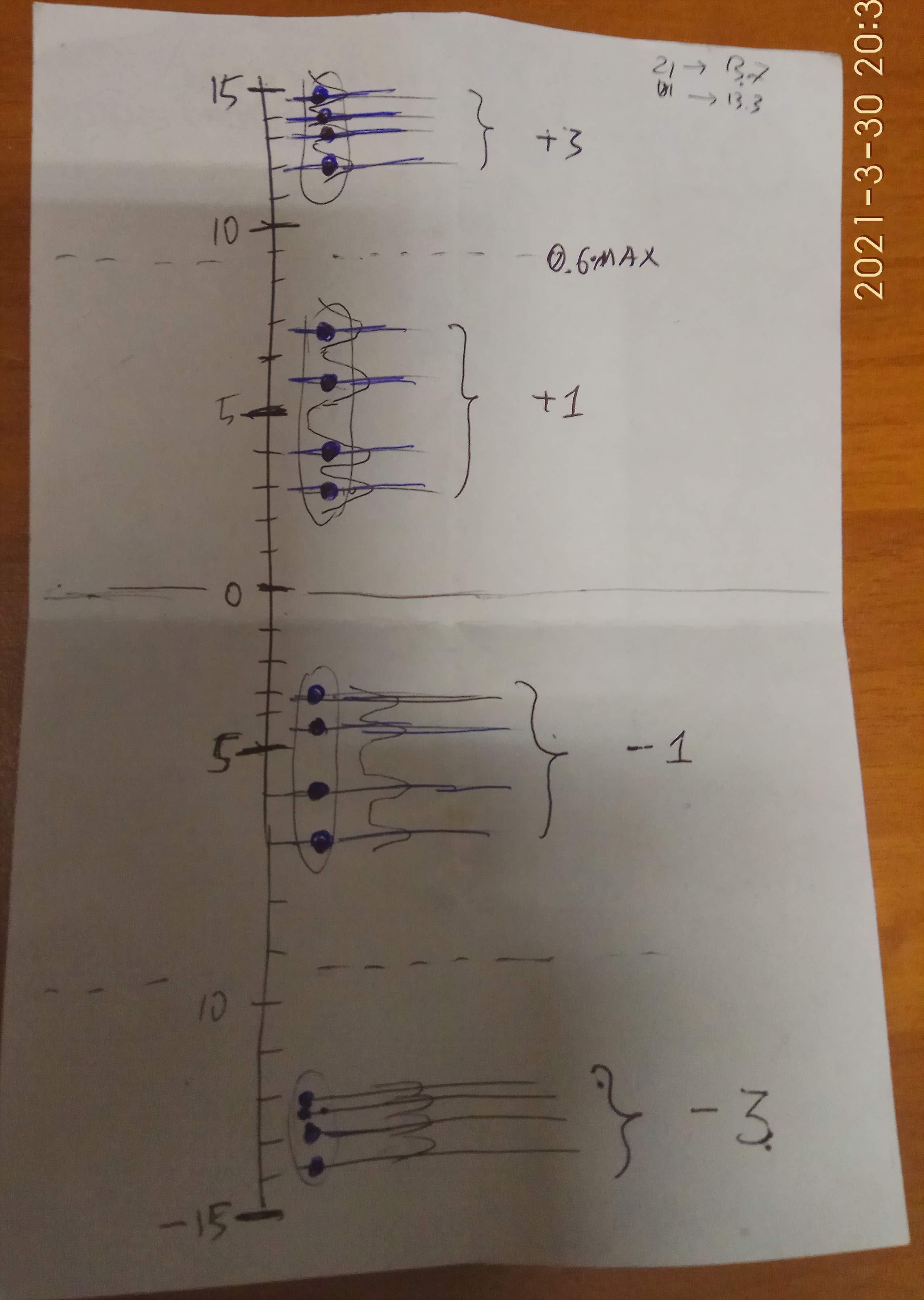
Увеличить
Но это как-бы в идеале. Если так будет на практике, то проблем с разделением символов по уровням не должно быть, поскольку можно чётко провести линии раздела по уровням. Кстати, тут они получаются около 0.6 от максимальных, то есть те самые 5/8, которые задействованы в исходнике DSD |
|
|
Дата: 30 Мар 2021 21:34:49 · Поправил: killer258 (31 Мар 2021 08:26:06)
#
Я наконец написал процедуру, которая , пробежав по записи, собрала статистику, сколько раз встречалось то или иное значение аналогового уровня. И нарисовал график, чтоб посмотреть, что же у меня там имеет место. Для двух случаев. Красным цветом нарисовано распределение для случая, когда сэмплы берутся в самый максимально неподходящий для этого момент, то есть не по центрам символьных интервалов, а по границам их. Распределение получилось такое спадающее от центра к краям. А зелёным цветом показано, каким стало распределение, если берёшь сэмплы в серединах символьных интервалов. Бросается в глаза, что стало меньше значений вблизи нуля и выросли по бокам четыре максимума, а в самых крайних даже видно расщепление на 4 наиболее вероятных значения:
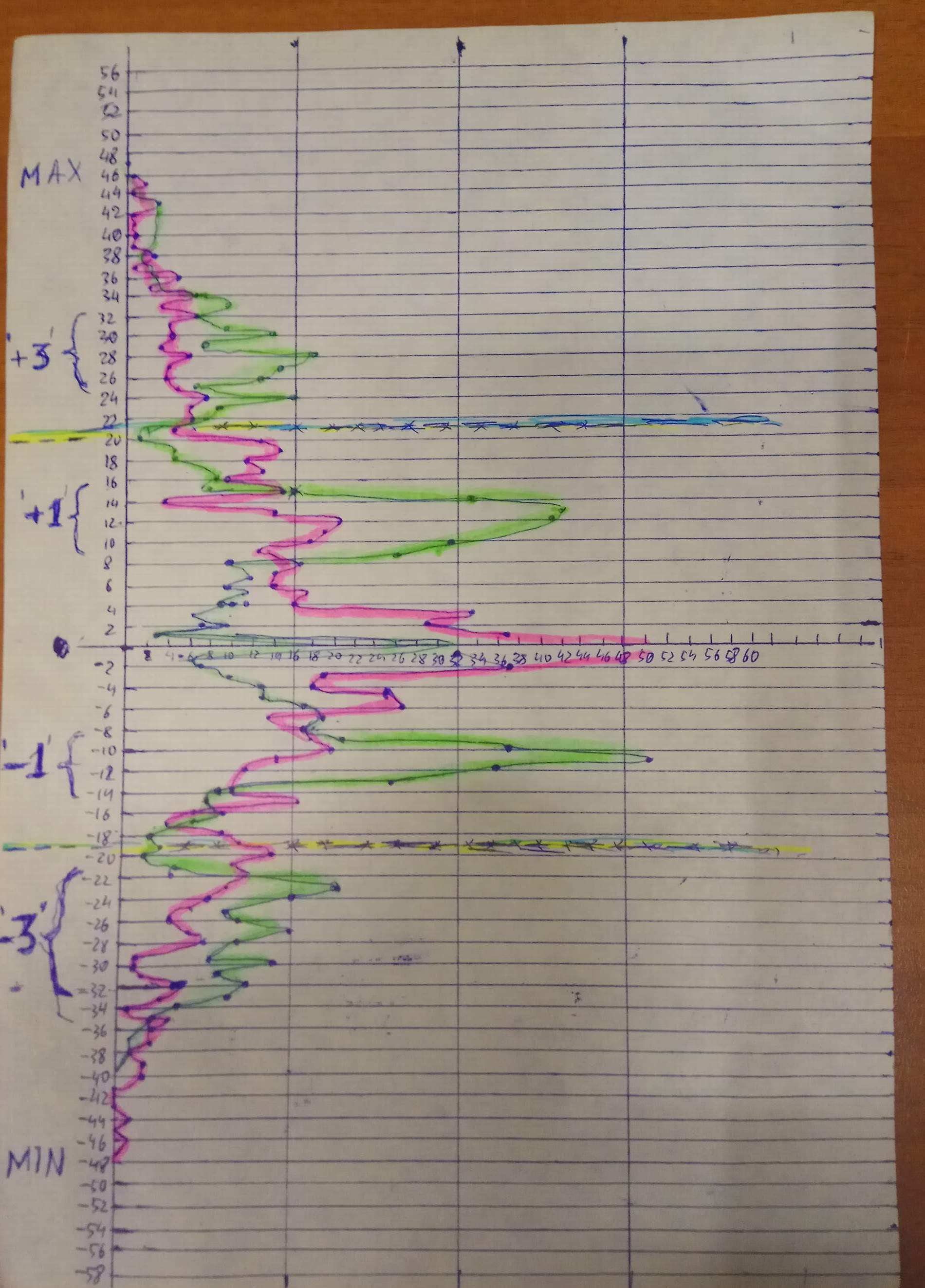
Увеличить
и видно, что на зелёной кривой появились два минимума, почти до самого нуля, там где надо проводить границу раздела между +1/+3 и -1/-3. Красная линия до нуля нигде не опускается, плавно спадая к краям. Видимо, чем точнее попадёшь в центры считывания, тем наверное, сильнее прорисуются максимумы и провалы между ними. Если б это можно было оценивать не на глаз, а в автоматическом режиме, то это наверное, тоже было бы работающим методом по нахождению правильных моментов считывания.
Для удобства построения графика значения сэмплов были уменьшены в 256 раз, то есть стали однобайтные. Надо будет попробовать провести декодирование с найденными уровнями сравнения, и если будет приемлемый результат, то это будет означать, что для записей разрешение в 16 бит избыточно и что можно обойтись 8-битным квантованием уровней сигнала с дискриминатора.
Кстати, у меня на этой записи судя по графику, границы раздела между +1/+3 и -1/-3 проходят по уровню примерно 0.43 от максимального значения. Это не 5/8 и не 1/3, а что-то между ними.
И, ещё я думаю, надо будет поэкспериментировать с фильтрами и тд, чтоб посмотреть, как это влияет на уровни раздела и минимальное количество отсчётов, приходящееся на них, и тогда можно будет поискать самые оптимальные условия для правильного декодирования |
|
|
Дата: 31 Мар 2021 19:36:25 · Поправил: killer258 (01 Апр 2021 10:33:46)
#
Из графика распределения уровней вроде бы чётко видно, где проходит раздел между +1 и +3, и где между -1 и -3
Но когда пытаюсь декодировать, то даже производя выборки в серединах символьных интервалов, всё равно получается, что преамбула читается без ошибок, но NAC и UnitID идут с ошибками по отдельным символам +1/-1, которые кое где ошибочно воспринимаются как +3/-3, то есть уровень раздела низок вроде как бы.. А если чуть-чуть приподнимаю уровни раздела при принятии решения, то тогда NAC и Unit ID начинают читаться верно, но зато тогда в преамбуле некоторые -3 начинают читаться как -1, которых в ней быть не может.
Не знаю, как избавиться от появления "спорных" уровней на границах разделения, как сделать, чтоб уровни "ложились" бы подальше от границы , отделяющей +1 от +3 и -1 от -3
Без этого декодирование с приемлемым уровнем ошибок не получается.
|
|
|
Дата: 01 Апр 2021 11:41:08 · Поправил: killer258 (01 Апр 2021 16:19:20)
#
Думаю, что тут ситуацию смог бы улучшить фильтр "корень из приподнятого косинуса с альфой 0.2" . Но я не знаю, как самому программно такое написать, а если делать аппаратно на R,L,C , то подозреваю, что в железе фильтр с такими параметрами скорее всего невозможен.
Хотя.. эксперимент можно было бы продолжить, если б кто-нибудь из здесь присутствующих смог бы мою запись с дискриминатора с помощью программы SA (или каким-либо другим инструментом) обработать в соответстви с характеристиками этого фильтра и выложить здесь уже профильтрованную запись , я бы попробовал снова её отфильтрованную продекодировать и будет ясно, насколько это может помочь.
|
|
|
Дата: 07 Апр 2021 15:06:18 · Поправил: killer258 (07 Апр 2021 16:06:59)
#
Ошибки декодирования так и не удаётся убрать. Я попробовал слегка опрямоуголить вершины импульсов в записи и увеличить крутизну фронтов. Идея была реализована так : программа пробежалась по всем отсчётам wav файла, находя в нём такие отсчёты, в окрестности которых слева от них производная была положительной, а справа была отрицательной, то есть это были локальные максимумы (вершины импульсов). В случае нахождения таких максимумов программа заменяла ближайшие к вершине несколько отсчётов на значение в этой самой вершине, то есть делала горизонтальную полочку на вершине. Аналогичная операция была проведена в окрестностях точек минимумов на "осциллограмме" сигнала. Помимо этого была проведена корректировка фронтов. Если два соседних семпла (при 48 кгц частоте семплирования) отличались друг от друга по уровню более чем на 10%, то значит, это был фронт или спад, в таком случае текущее значение заменялось на значение следующего семпла. Я полагал, что если имеют место незначительные ошибки моментов взятия символа, приходящихся на крутые скаты импульсов, где малейшая ошибка по времени сильно изменит аналоговый уровень снятого значения ,то такая коррекция фронтов и вершин должна была по идее, помочь решить проблему неверного принятия решений о наличии уровня +1 или +3.
Осциллограмма такого обработанного wav файла стала похожей на сциллограмму регенерированного апкосигнала из файлов, имеющихся на нашем форуме, но однако, количество ошибок декодирования это не уменьшило :-(
Придётся наверное, набраться терпения и по значениям отсчётов в файле вручную построить на миллиметровке по точкам кривую сигнала с привязкой миллиметровых линий к интервалам семплирования, ( построить график на участке преамбулы и ближайшего после неё хотя бы одного десятка символьных интервалов) , расставить на кривой все моменты взятия символов и визуально посмотреть, на что они там попадают и какие в этих точках оказываются уровни аналогового сигнала. Может, тогда что-нибудь прояснится.
|
|
|
Дата: 07 Апр 2021 19:15:37
#
killer258
запись с дискриминатора с помощью программы SA (или каким-либо другим инструментом) обработать в соответстви с характеристиками этого фильтра и выложить здесь уже профильтрованную запись
В SA вроде как реализована LPF и RRC фильтрация. По моему опыту, RRC более к DMR подходит, но не к апке. А так, давайте
запись на попробовать, можно через LPF пропустить, картинка границ уровней в демодуляторе после него заметно лучше.
|
|
|
Дата: 07 Апр 2021 20:45:48 · Поправил: killer258 (07 Апр 2021 21:19:30)
#
Ок, файл записи выложу чуть позднее, там небольшой отрывочек, около 20 килобайт, записан один пакет, содержащий около тысячи символов, запись демодулированного сигнала, сохранённаяя программой HDSDR с битрейтом 48 киловыборок в секунду, моно, 16 бит.
А вот я наконец нарисовал вручную по точкам график сигнала во время преамбулы (слева от вертикальной красной черты) и 19 символов идущих сразу после неё. Горизонтальная красная линия- это нулевой уровень.
Крупные клетки (1 см) по горизонтали соответствуют символьному периоду 208.3 мкс, миллиметрики соответствуют семплам звуковухи (20.8 мксек, 10 семплов на символьный интервал), на фотке мелкие линии не видны, но они есть. Красными точками я показал моменты взятия символов. По преамбуле всё соответствует, видно, что моменты правильные, но пытаясь продолжить это дальше, вижу , что уже на втором, пятом и одиннадцатом символах грубейшая ошибка взятия, так как момент взятия пришелся на переход графика через ноль - это ни в какие ворота не лезет (обведено большими кружочками), такие символы не отнести ни к +1, ни к -1.
Причём в целом момент взятия символов выбран правильно, потому что таких взятий в нуле получается что-то около пяти на тысячу, а при сдвиге момента взятия впреред или назад от оптимального момента их количество начинает исчисляться десятками.
Короче, вот как это выглядит:
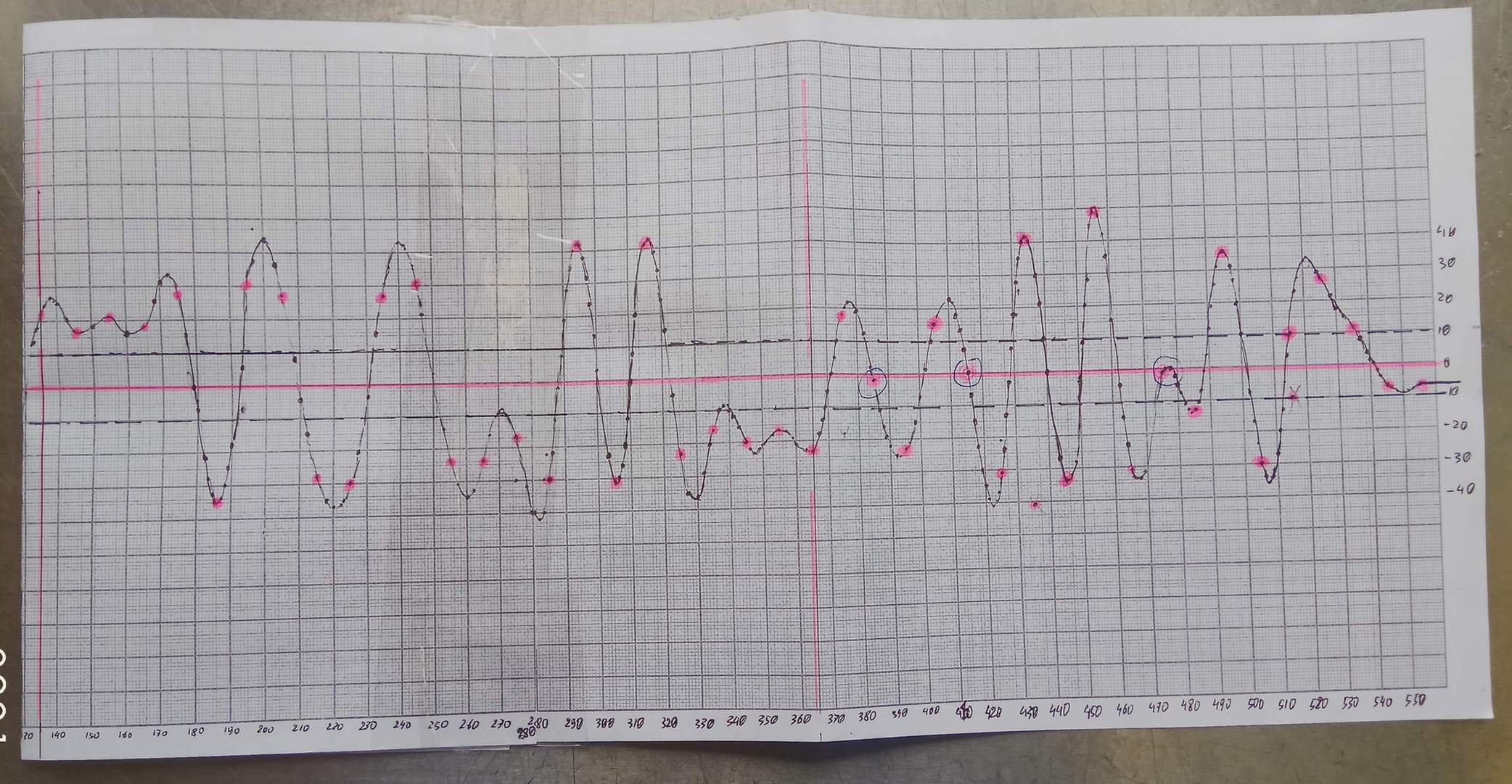
Увеличить
Для сопоставления, так выглядит образец преамбулы (вертикальные штриховые линии пересекают график в правильные моменеты взятия ) :
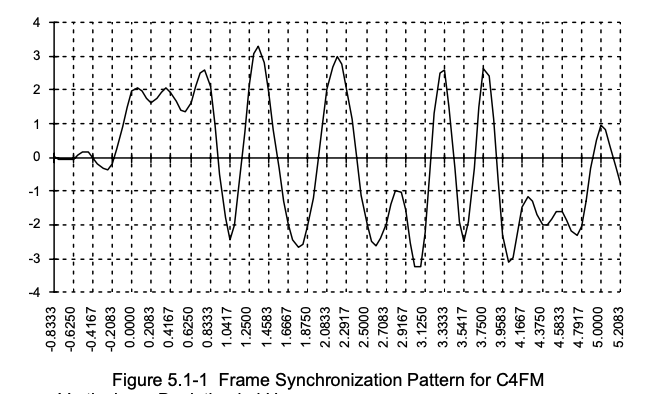
Увеличить
(начинается преамбула с 0.0000 и заканчивается на 4.7917 , содержит ровно 24 символа)
и вторая проблема- после преамбулы первый и четвертый символы должны быть +1, а здесь их уровни таковы, что они воспринимаются как +3
Это я знаю точно, потому что эти 6 символов (12 бит) -это NAC, равный 0х2С..., а для этого должно быть здесь первые 4 символа +1-1 -3+1 ... , а вместо этого они читаются как +3-1 -3+3
Если слегка приподнять порог разделенияя, то эти неверные +3 превратятся в +1, но тогда в преамбуле некоторые уровни -3 начнут неверно читаться как -1 (в нижней половине, где они опасно близко подходят к разделительной линии). То есть при сигнале , какой есть, не всегда удается отделить правильно +1 от +3
А вот собственно и запись сигнала, с которым я работаю :
http://www.radioscanner.ru/uploader/2021/stat20.wav
Это не IF I/Q запись, это AF запись после демодуляции в HDSDR
KarapuZ,попробуйте её обработать RRC . Хочу посмотреть, изменится ли что-нибудь в распределении уровней. DSD подобный фильтр сигнала использует.
LPF наверное нет смысла, так как это и в HDSDR есть возможность делать, обрезая демодулированный сигнал регулируемым фнч с довольно крутым срезом. У меня там при записи была выставлена полоса демодулированного сигнала до 2.88 кгц. |
|
|
Дата: 08 Апр 2021 00:49:47
#
killer258
Это не IF I/Q запись, это AF запись после демодуляции в HDSDR
Лучше конечно необработанный материал в IQ предоставить, ну да ладно, что есть...
попробуйте её обработать RRC
Исходник и резалт после RRC 0,2 , вид уровней в демодуляторе:
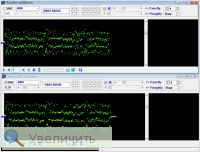
Запись после фильтра: http://www.radioscanner.ru/files/download/file21725/rrc_02.wav |
|
|
Дата: 08 Апр 2021 18:23:49 · Поправил: killer258 (08 Апр 2021 18:25:26)
#
Имеется незначительное улучшение. Но тут сейчас я обнаружил, что сам источник был не очень, несмотря на очень хороший уровень в эфире, даже сам DSD его декодирует со множеством ошибок (ERR13,ERR14). Попробовал пересесть на другой управляющий канал, там, хоть уровень и меньше, но DSD декодирует его почти совсем без ошибок.
Придётся с этой частоты писать файл для экспериментов. Может, с ним лучше получится.
|
|
|
Дата: 08 Апр 2021 18:54:07 · Поправил: killer258 (08 Апр 2021 19:27:57)
#
|
|
|
Дата: 08 Апр 2021 19:42:27
#
|
|
|
Дата: 08 Апр 2021 21:46:52 · Поправил: killer258 (08 Апр 2021 21:51:39)
#
|
|
|
Дата: 08 Апр 2021 23:44:12
#
Да, нормальная запись.
Опишу последовательность обработки в SA.
Преобразование квадратур в вещественный сигнал> полосовой фильтр 12,5 kHz> ЧМ демодулятор>
ФНЧ 0-2,8 kHz> передискретизация 96 kHz на 48 kHz> RRC =0,2. Плюс, была произведена коррекция
частоты манипуляции.
Вид уровней в демодуляторе:
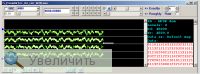
Результат: http://www.radioscanner.ru/files/download/file21726/rrc_02_corr_br.wav |
|
|
Дата: 09 Апр 2021 08:43:19 · Поправил: killer258 (09 Апр 2021 21:31:46)
#
Продекодировал один из фреймов в скорректированном вами сигнале после вашего демодулятора. (rrc_02_corr_br.wav)
вот что получилось в результате компарирования уровней , начиная с преамбулы и далее:
+3 +3 +3 +3 +3 -3 +3 +3 -3 -3 +3 +3 -3 -3 -3 -3 +3 -3 +3 -3 -3 -3 -3 -3 (преамбула)
далее:
+1 -1 -3 +1 +1 +3 +1 -3 -3 +1 -3 -1 +1 +1 -3 +3 -1 +1 +1 -1 -3 +1 +3 -3 -1 -3 +3 -3 +1 +3 -3 -1 -1 +1 +1 +1 +1 +1 +1 +1 +1 +1 +1 +1 +1 +1 +1 -3 +3 +3 +3 +3 +3 -3 +3 +3 -3 -3 +3 +3 -3 -3 -3 -3 +3 -3 +3 -3 -3 -3 -3 -3 +1 -1 -3 +1 +1 +3 +3 -3 +1 +1 -3 -1 +3 -3 +1 +3 +1 +3 -1 -3 +3 +1 -3 -1 +3 -1 +3 -3 -3 -3 +3 -1 +1 +1 -1 -1 +3 +1 -1 +3 +3 -1 +3 +1 +1 +3 +3 -1 +3 +3 -1 +3 -3 -1 +3 +1 -1 +1 +3 +3 +1 -1 +1 -1 +1 +3 +1 -1 +1 -1 -3 +3 +1 +3 -3 +1 +1 -1 -3 +1 -1 -3 +3 -3 +3 +1 -1 +1 -3 +3 -3 -3 -3 -3 +1 +3 +1 +3 -3 -3 -1 -3 +1 +1 -3 +1 +1 +1 -1 +1 +3 +1 -1 +1 -3 +3 -1 +1 +1 -1 -1 +1 +1 -3 +1 +3 +1 +1 +3 -1 +1 -3 -3 -3 +1 -1 +1 -1 +1 -1 -3 -1 +1 -1 +1 -1 -1 +3 -3 +3 +3 +3 -1 +3 -3 -1 +1 -1 -3 -1 +3 -3 -3 +1 -1 -3 -3 -3 +1 +1 -1 -3 -3 +1 -1 +3 -3 +1 -1 +1 -1 -3 -1 +1 +1 -1 -3 +1 -1 -1 -3 -3 -3 -1 +1 -1 +3 +3 +1 -1 +1 -3 +1 +3 +1 -1 +1 -1 -3 -1 -3 -1 +1 -1 +1 +1 +1 -1 +1 -1 +1 +3 -3 +1 -1 +1 -1 -1 -1 +1 -1 -3 -3 +1 +3 +1 +3 -3 +3 +1 -1 +1 -1 +1 -1 +1 -1 +1 -1 +1 -1 +1 -1 +1 -1 +1 -1 +1 -3 +3 +3 -1 +3 -1 +3 -3 +1 -1 +1 -1 +1 -1 +1 -1 +1 -1 +1 -1 +1 -1 +1 -1 -3 -3 -1 +1 -3 +1 -3 -1 +1 -1 +1 -1 +1 -1 +1 -1 +1 -1 -1 +1 -1 +1 -1 +1 -1 -1 -3 -1 -3 +1 +1 +1 -1 +1 -1 +1 -1 +1 -1 +1 -1 +1 -1 +1 -1 +1 -1 +1 -1 +1 +1 +1 -3 -1 +3 +3 +3 +3 +3 -3 +3 +3 -3 -3 +3 +3 -3 -3 -3 -3 +3 -3 +3 -3 -3 -3 -3 -3 +1 -1 -3 +1 +1 +3 -3 +1 +1 -1 +1 -1 -3 +3 +1 -1 -1 -1 +3 -1 +3 -1 -3 -1 +3 -1 +1 +1 -1 +3 -1 +3 -1 +1 -1 -1 +1 -3 -1 +1 -1 +1 -1 +3 +1 -1 -1 -3 -3 -1 +3 +3 +1 -1 -3 +1 +3 -3 +3 +3 -3 -3 -1 +1 +1 -1 +1 -1 +1 -1 +3 +3 -1 +3 -3 -3 +1 -1 +1 -1 -3 +3 -3 -1 +3 -1 -3 -1 +1 +1 -1 +1 -1 +1 -1 +1 -1 +1 -1 +3 -1 +1 -1 +1 -1 +3 -3 +3 -3 +1 -3 -1 -3 +1 -1 +1 -1 +1 +3 -1 +1 +3 -3 +1 +3 +1 +1 -1 +1 -1 -3 +3 +1 -3 +1 +3 +3 +1 +1 -1 +1 -1 +3 -3 +1 -1 -3 -3 +3 -3 +1 +3 -3 -1 -1 -1 +3 +1 +1 +1 -1 +3 +1 +3 -1 +1 -1 +1 +3 +1 +1 +1 +3 +3 -1 +1 -3 +3 +1 +1 +3 +1 +3 +1 +1 -1 +1 -1 +3 +1 -1 -1 +3 -3 +1 +1 +3 +1 +3 +1 +3 +3 +3 -1 -1 -1 -1 -1 -3 -1 +3 -3 +1 -1 +1 -1 -3 +3 -3 -3 +3 +1 +3 -3 +1 -3 +3 -1 -3 -1 -3 +3 -3 +1 -1
Пока ещё не было времени поколупаться в этом массиве , перевести все символы в двоичку, проверить всё на правильность с помощью БЧХ, Рида-Соломона и Голея, и определить, сколько фреймов в этот массив попало и каких именно типов они окажутся, но на вскидку первые символы идущие после преамбулы (выделено жирным шрифтом) на этот раз декодируются абсолютно верно:
+1 -1 -3 +1 +1 +3
исходя из определения дибитов +3 ->01, +1->00, -1->10, -3->11
получается в битовом виде это 0010 1100 0001, то есть это 0х2с1 в шестнадцатиричке.
эти первые 6 символов после преамбулы есть не что иное как NAC, а он, как я уже установил через DSD , в этой записи действительно равен 2С1
PS: KarapuZ, благодарю вас. Видимо, ваш демодулятор оказался заметно точнее, чем тот, который находится в составе HDSDR
Плюс, была произведена коррекция частоты манипуляции. А это как? можно подробнее?
Окно правильного детектирования кстати, оказалось равным одному интервалу семплирования (10% от символьного интервала в данном случае). стоит применить момент взятия значений на 1 семпл раньше или на один позже оптимального, и уже начинают появляться ошибки. (в правильном варианте ни один из моментов взятия символа не пришёлся на аналоговое значение, равное или почти равное нулю, а вот в неправильных вариантах уровни взятия +0 и -0 присутствуют в целом ряде мест)
Вообще, распределение аналоговых значений символов по уровням на этот раз оказалось неплохим:
+ уровень -53 (досюда редко кто долетает)
+
++
++
++
+
+++++
+++++
+++++++
++++++++
+++++++++
+++++
+++++++
++++++++
+++++++++++++++++++++++++ здесь максимум попаданий для "-3" (уровень -39)
++++++++++++++
+++++++++++
+++++++++++++++
+++++++++++++++
++++++++
++++
++++
++++++
++
++
++
+
граница разделения между -1 и -3, уровень -25 (в ёё окрестности практически нет попаданий)
+
+
++
+++++
+++
++++
++
++++++
++++++++
+++++++++
+++++++
++++++++++++++++++
+++++++++++++++++
++++++++++++++++++++
++++++++++++++++++++++ здесь максимум попаданий для "-1" (уровень -13)
++++++++++++++++
+++++++++++++++++++
+++++++++++++++++
++++++++++++
++++++
+++++++++++
+++
+++
++
++
+
+
+
выше отрицательные
=== Центр. Нулевой уровень (Ноль ) ==== при норм сигнале и правильном моменте взятия здесь ничего нет
ниже положительные
++
++++
+++++++
+++++++++++++++
++++++++++++++++++++++
++++++++++++++++++++++++++++++++++
++++++++++++
+++++++++++
+++++++++++++++++++
++++++++++++++++++++ здесь максимум попаданий в "+1" (уровень 13)
+++++++++++++++++++++++++++
+++++++++++++++++++++++++++
+++++++++++++++++
+++++++++++++++++++++
+++++++++++++
+++++++++
++++
++++++
++++
++
+
+
граница разделения между +1 и +3, уровень =25 (в ёё окрестности практически нет попаданий)
++
+
++
++
+++++
+++++++
+++
++++
++++++
++++++++
++++++++
+++++++++++
++++++++++++
+++++++++
+++++++++++++++++++++++ здесь максимум попаданий в "+3" (уровень 39
++++++++++
++++++++++++
++++++++++++++
++++++++++++
++++++++
++
+
+++
+
+
+ уровень 50 (досюда редко кто долетает)
Так выглядела картинка распределения уровней символов при правильном моменте их "взятия"
При неправильном же моменте взятия "горбы" исчезают,и получается распределение близкое к равномерному, с плавным спадом в обе стороны от нуля. Приводить картинку этого распределения не буду, чтоб не засорять здесь.
Кстати, надо заметить, что здесь оптимальными оказались уровни разделения в 1/3 от максимальных значений семплов , а не 0.625, как в DSD
Причём в "правильных "точках взятия уровни всегда меньше максимальных. |
|
|
Дата: 09 Апр 2021 12:26:27 · Поправил: killer258 (09 Апр 2021 17:41:45)
#
Надеюсь, что и остальное окажется верным.
после NAC дальше идёт +1 -3 , что в двоичке будет 0011, а это должно означать , что DUid характерный для TDU фрейма.
Если это фрейм TDU , то дальше там ничего особо интересного в нём нет, дальше должны будут быть только проверочные биты BCH_parity(47)...BCH_parity(0) и ещё два статусных бита туда затесались после шести BCH битов
Terminator Data Unit по документации протокола выглядит так:
№ Bit 1 Bit 0
0> 0 1 (начало преамбулы)
1> 0 1
2> 0 1
3> 0 1
4> 0 1
5> 1 1
6> 0 1
7> 0 1
8> 1 1
9> 1 1
10> 0 1
11> 0 1
12> 1 1
13> 1 1
14> 1 1
15> 1 1
16> 0 1
17> 1 1
18> 0 1
19> 1 1
20> 1 1
21> 1 1
22> 1 1
23> 1 1 (конец преамбулы)
24> NAC(11) NAC(10)
25> NAC(9) NAC(8)
26> NAC(7) NAC(6)
27> NAC(5) NAC(4)
28> NAC(3) NAC(2)
29> NAC(1) NAC(0)
30> DUID(3) DUID(2)
31> DUID(1) DUID(0)
32> BCH_parity(47) BCH_parity(46)
33> BCH_parity(45) BCH_parity(44)
34> BCH_parity(43) BCH_parity(42)
35> SS(1) SS(0) status1 биты
36> BCH_parity(41) BCH_parity(40)
37> BCH_parity(39) BCH_parity(38)
38> BCH_parity(37) BCH_parity(36)
39> BCH_parity(35) BCH_parity(34)
40> BCH_parity(33) BCH_parity(32)
41> BCH_parity(31) BCH_parity(30)
42> BCH_parity(29) BCH_parity(28)
43> BCH_parity(27) BCH_parity(26)
44> BCH_parity(25) BCH_parity(24)
45> BCH_parity(23) BCH_parity(22)
46> BCH_parity(21) BCH_parity(20)
47> BCH_parity(19) BCH_parity(18)
48> BCH_parity(17) BCH_parity(16)
49> BCH_parity(15) BCH_parity(14)
50> BCH_parity(13) BCH_parity(12)
51> BCH_parity(11) BCH_parity(10)
52> BCH_parity(9) BCH_parity(8)
53> BCH_parity(7) BCH_parity(6)
54> BCH_parity(5) BCH_parity(4)
55> BCH_parity(3) BCH_parity(2)
56> BCH_parity(1) BCH_parity(0)
57> 0 0 (Nulls биты)
58> 0 0
59> 0 0
60> 0 0
61> 0 0
62> 0 0
63> 0 0
64> 0 0
65> 0 0
66> 0 0
67> 0 0
68> 0 0
69> 0 0
70> 0 0
71> SS(1) SS(0) Status2 bits
Проверю чуть позже всё по БЧХ, когда с его алгоритмом разберусь, сейчас пока немного не до этого к сожалению.
Немного смущает фраза из документа "The simple Terminator Data Unit is transmitted at
the end of a voice message. " Если TDU передаётся, как они там пишут, в конце голосового сообщения, то что же тогда он делает в канале управления?? Скорее всего, он и там тоже используется видимо.
|
|
|
Дата: 09 Апр 2021 13:52:54 · Поправил: killer258 (10 Апр 2021 13:50:37)
#
более внимательный просмотр отдекодированного куска показал, что в нём кроме TDU, содержатсся ещё два фрейма, тоже предваряемых преамбулой. Второй с DUID 0111 , идентифицирован как TSBK, а вот последний (третий) фрейм имеет DUID=1100, это значит, что попался PDU (Packet Data Unit)
вот его содержимое наверное, будет поинтереснее .
Вот он (урезан с конца, так как не поместился полностью в исследовавшийся кусок файла):
"+3 +3 +3 +3 +3 -3 +3 +3 -3 -3 +3 +3 -3 -3 -3 -3 +3 -3 +3 -3 -3 -3 -3 -3" (преамбула)
+1 -1 -3 +1 +1 +3 -3 +1 +1 -1 +1 -1 -3 +3 +1 -1 -1 -1 +3 -1 +3 -1 -3 -1 +3 -1 +1 +1 -1 +3 -1 +3 -1 +1 -1 -1 +1 -3 -1 +1 -1 +1 -1 +3 +1 -1 -1 -3 -3 -1 +3 +3 +1 -1 -3 +1 +3 -3 +3 +3 -3 -3 -1 +1 +1 -1 +1 -1 +1 -1 +3 +3 -1 +3 -3 -3 +1 -1 +1 -1 -3 +3 -3 -1 +3 -1 -3 -1 +1 +1 -1 +1 -1 +1 -1 +1 -1 +1 -1 +3 -1 +1 -1 +1 -1 +3 -3 +3 -3 +1 -3 -1 -3 +1 -1 +1 -1 +1 +3 -1 +1 +3 -3 +1 +3 +1 +1 -1 +1 -1 -3 +3 +1 -3 +1 +3 +3 +1 +1 -1 +1 -1 +3 -3 +1 -1 -3 -3 +3 -3 +1 +3 -3 -1 -1 -1 +3 +1 +1 +1 -1 +3 +1 +3 -1 +1 -1 +1 +3 +1 +1 +1 +3 +3 -1 +1 -3 +3 +1 +1 +3 +1 +3 +1 +1 -1 +1 -1 +3 +1 -1 -1 +3 -3 +1 +1 +3 +1 +3 +1 +3 +3 +3 -1 -1 -1 -1 -1 -3 -1 +3 -3 +1 -1 +1 -1 -3 +3 -3 -3 +3 +1 +3 -3 +1 -3 +3 -1 -3 -1 -3 +3 -3 +1 -1 ..... ....
NAC тот же, 2С1, а вот DUID уже другой: -3+1 - это в битах будет 1100 (Packet Data Unit)
Чуть позже попробую поковыряться в его содержимом.
|
|
|
Дата: 10 Апр 2021 12:00:45 · Поправил: killer258 (11 Апр 2021 09:45:36)
#
Теперь, когда проблему с разделением уровней в 4-уровневом сигнале "как-бы" решили, можно уже переводить все эти "+1","+3","-1","-3" в двоичку. Можно бы и сразу в байты, но там мешают вставленные после каждых 70-ти бит (микрослот это у них называется) пары статусных битов, будь они неладны, их сначала надо повыдёргивать из потока :-( А может, и не потребуется выдёргивать, микрослот ведь всё равно не кратен одному байту , так что придётся парсить по-иному:-)
Всего возможны 4 значения статусных битов:
01 — занято;
11 — не занято;
00 — неизвестно
10 — неизвестно
После того, как был найден правильный момент взятия символов в начале файла (rrc_02_corr_br.wav), содержащем, как позднее было выяснено, целых 18 фреймов (не считая самого первого, начинавшегося не с начала и последнего, обрезанного раньше чем он закончился), я решил пройтись с этим моментом взятия символов до самого конца файла, считывая каждый десятый семпл. Весь файл до самого конца прочелся без ошибок кадрирования. Я полагал, что каждый фрейм будет начинаться с произвольной фазы несущей, и нужно будет каждый раз находить правильный момент считывания, но оказалось, что можно с найденным моментом шпарить до самого конца файла. В него попало, как я уже отметил, 18 фреймов.
Тут упоминалась коррекция символьной частоты, произведенная участником KarapuZ
Может быть, это благодаря коррекции частоты файл читается "на одном дыхании"?
все обнаруженные фреймы принадлежат сети 2С1, и вот какие у этих фреймов оказались DUID:
0111
0111
0111
1100
0011
0111
0111
0111
1100
0011
0111
0111
0111
1100
0011
ну и так далее. Видно, что в этом куске файла всё время постоянно чередуются раз за разом вот эти вот пять фреймов трёх видов (по DUID) :
0111 // этот фрейм - Trunking Signaling block (TSBK)
0111 // этот тоже.
0111 // и этот тоже .
1100 // а вот это PDU (Packet Data Unit)
0011 //а это TDU - "отбой" , короткий терминатор-пустышка (Terminator Data Unit) который я уже встречал
|
|
|
Дата: 10 Апр 2021 13:44:11 · Поправил: killer258 (11 Апр 2021 09:46:38)
#
из несущих интересный контент здесь два типа фреймов:
1) транкинговые сигнальные блоки TSBK и
2) PDU
других типов тут похоже, что не встречается.
TSBK оказались содержащими в себе 10 микрослотов по 70 бит, разделённых статусами, причём статусные биты после каждого микрослота 10 и 11.
По документации в TSBK базы должно быть 5,8 , 10 и более микрослотов.
Вот только по этой документации это может быть как синглблок так и мультиблок, и как понять, который из них?
в последнем случае октеты означают другое.
А у PDU оказалось только 7 микрослотов. (вообще надо бы перепроверить)
Теперь наверное, пора заняться препарированием отдельных микрослотов у TSBK и у PDU фреймов.
|
|
|
Дата: 10 Апр 2021 14:42:07 · Поправил: killer258 (11 Апр 2021 09:50:01)
#
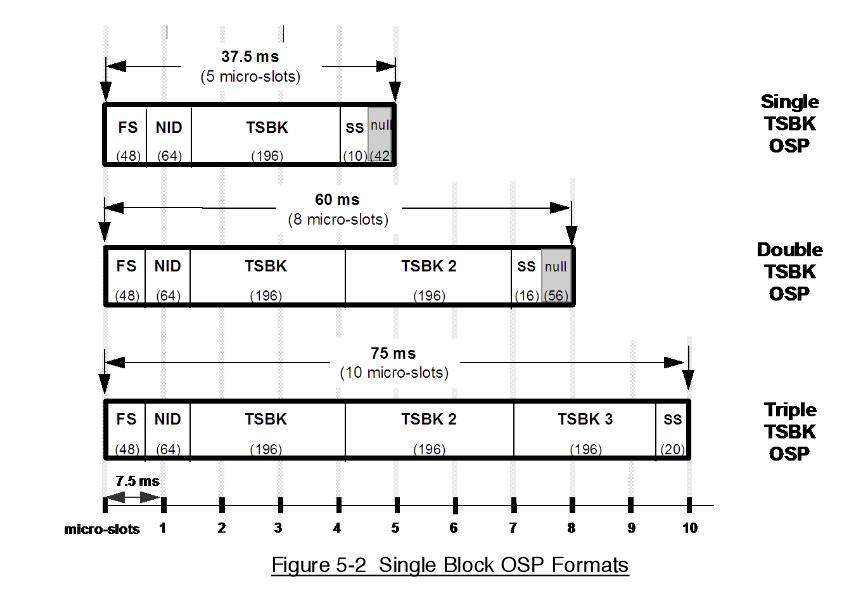
пока из описания не смог понять , размер TSBK блока 196 бит - это указано с учётом статусных битов, попадающих в него или без их учёта. На картинке нарисовано так, будто все статусные биты собраны в конце блока, но я сомневаюсь, что это правильно и ли я что-то не так понимаю. Если с этим не разобраться, то я TSBK блоки неправильно разобью на октеты
Я вот об этом:
Увеличить
SS у них вообще-то означает Status Symbols , но тут они или неверно написали, и тогда это какая-нибудь контрольная сумма может быть имелась в виду в конце, а не статусные символы, собранные в кучу судя по обьявленному количеству бит, или я их не так понял. Непонятно..
Если с этим не разобраться, то я битовую последовательность в блоке неправильно разобью на вот эти октеты :
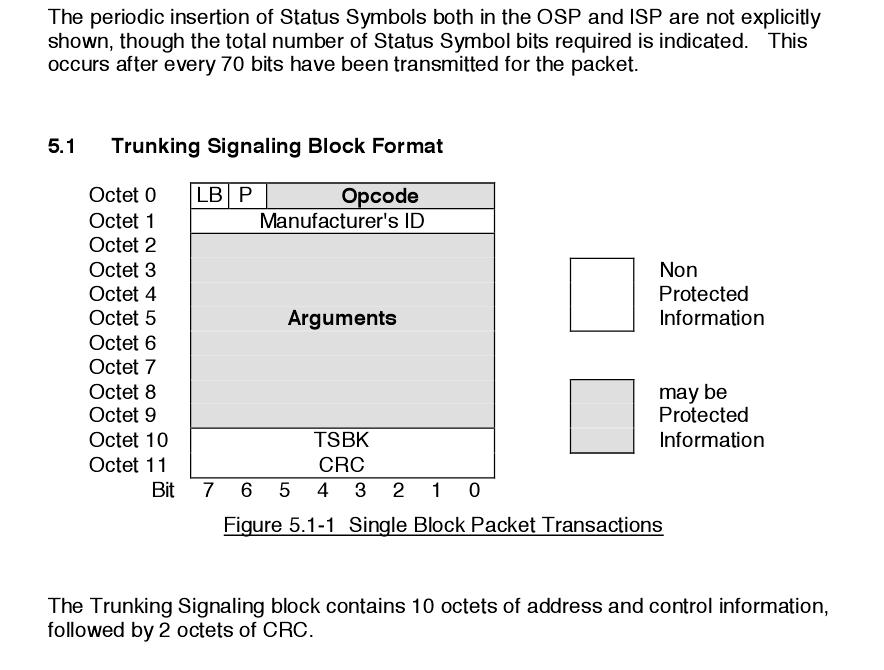
Увеличить так как их границы сдвинутся
и осталось неясным, что такое SS в конце блока перед Null
Cодержимое октетов Arguments будет зависеть от того, какой Opcode.
то есть от кода операции. Надо будет найти, какой код у операции, в случае , когда БС выделяет мобильной станции с каким-то TGID какой-то номер канала. Этой информации окажется достаточно, чтобы перестроить на этот канал приёмник и послушать там этого абонента. |
|
|
Дата: 10 Апр 2021 19:39:56 · Поправил: killer258 (11 Апр 2021 09:52:56)
#
Всё та же непонятка про 196 бит . Ведь октет - это 8. Да и по описанию октетов видно, что там говорится о битах 7...0 того или иного октета. То есть, октет вроде как == байт. Но тогда 12 октетов будет 96 битов, а никак не 196.. Ну, плюс пара статусных ещё добавится, то есть 98 бит. А у них там на верхней картинке TSBK почему-то в 2 раза больше битов изображено - не по 98, а по 196 ...
|
|
|
Дата: 10 Апр 2021 21:25:07 · Поправил: killer258 (10 Апр 2021 22:26:18)
#
на данный момент надо разобрать хотя бы один из фреймов TSBK (их там три подряд идёт)..
Собственно, вот они в двоичке, я их вычленил из остального: (DSD его показывает их как TSDU
и в одном из них для TGID=1391 назначается канал 2-1806,(451.2875 мгц) а для TGID=1310 назначается канал 2-1810 (451.3125 мгц))
первый TSBK:
//преамбула
01 01 01 01 01 11 01 01 11 11 01 01 11 11 11 11 01 11 01 11 11 11 11 11
// содержимое
00 10 11 00 00 01 01 11 00 00 11 10 01 11 00 01 00 01 10 11 01 00 11 10 01 10 01 11 11 11 01 10 00 00 10 00 10 11 00 11 10 00 10 00 10 10 01 10 00 11 10 01 01 00 11 00 11 11 01 01 11 11 00 10 11 10 11 00 00 10 11 11 00 10 01 10 11 00 10 00 11 01 01 10 10 10 11 00 10 11 00 11 10 00 10 01 01 00 10 10 10 11 10 10 00 01 11 01 00 11 10 00 10 00 00 00 10 00 10 11 00 01 11 00 10 10 00 01 01 01 11 10 10 00 00 10 11 01 00 10 00 10 00 10 00 10 00 10 00 10 00 10 00 10 11 10 11 00 11 01 01 00 10 01 11 00 10 00 10 00 10 00 10 00 10 00 10 00 10 00 10 10 11 01 01 11 00 11 10 00 10 10 00 10 00 10 00 10 00 10 00 10 00 10 00 10 11 10 00 10 00 00 00 10 00 10 00 10 00 10 00 10 00 10 00 10 00 10 10 00 10 11 00 11 11 00 01 00 10 00 10 11 10 00 10 00 10 10 01 11 10 01 00 10 01 00 01 11 01 10 01 01 00 10 00 10 00 01 11 00 00 10 11 11 00 10 11 11 01 01 00 10 10 01 01 00 10 11 00 10 01 11 11 10 00 10 01 01 11 10 00 10 00 11 00 00 10 00 01 10 11 11 10 00 10 00 00 00 10 00 10 00 01 00 00 01 10 11 01 00 10 01 11 11 01 11
Второй TSBK:
01 01 01 01 01 11 01 01 11 11 01 01 11 11 11 11 01 11 01 11 11 11 11 11 //преамбула
// содержимое
00 10 11 00 00 01 01 11 00 00 11 10 01 11 00 01 00 01 10 11 01 00 11 10 01 10 01 11 11 11 01 10 00 00 10 00 01 00 10 11 00 01 01 11 00 01 01 10 11 00 01 01 00 11 01 01 11 11 10 01 00 10 01 11 00 10 11 01 00 10 11 01 00 10 11 01 00 10 01 01 11 00 10 10 00 00 10 11 10 00 01 01 11 00 01 01 11 00 01 01 11 00 01 00 10 00 11 01 01 00 10 00 10 10 01 00 11 10 01 10 00 11 10 01 00 11 01 11 11 11 01 01 00 01 00 10 10 01 00 10 11 00 11 11 10 00 10 00 10 00 10 00 10 00 10 10 11 01 00 11 10 11 00 00 10 00 10 11 10 10 00 10 00 10 00 10 00 10 00 10 00 00 00 01 10 00 00 00 10 00 10 11 00 10 10 00 10 00 10 00 10 00 10 00 10 00 11 10 01 11 11 01 00 10 00 10 00 10 10 00 10 00 10 00 10 00 10 10 00 10 00 00 01 00 00 00 01 00 10 00 10 00 10 01 00 10 01 11 10 00 10 00 10 11 00 00 10 10 11 10 01 01 00 10 00 10 00 10 00 01 01 01 00 10 00 10 00 10 00 10 00 11 11 11 11 10 10 00 00 10 00 10 10 01 00 10 00 10 00 10 01 00 10 00 10 01 01 01 10 11 11 01 01 00 10 00 10 00 01 00 01 11 00 10 01 00 10 00 10 00 10 01 00 01 10 10
Третий TSBK:
01 01 01 01 01 11 01 01 11 11 01 01 11 11 11 11 01 11 01 11 11 11 11 11 //преамбула
// содержимое
00 10 11 00 00 01 01 11 00 00 11 10 01 11 00 01 00 01 10 11 01 00 11 10 01 10 01 11 11 11 01 10 00 00 10 11 01 00 10 11 00 00 10 00 10 00 10 11 00 10 00 10 00 10 11 11 01 00 11 10 00 10 01 11 11 00 11 10 00 10 00 10 00 10 00 10 00 10 00 10 10 11 01 10 10 00 01 11 10 11 10 00 10 00 10 00 10 00 10 00 10 00 10 00 10 00 00 01 11 01 11 00 10 00 10 00 10 00 10 10 00 10 00 10 00 10 00 10 00 10 11 01 00 00 00 10 11 10 00 10 11 10 11 10 01 00 00 10 00 10 11 10 00 10 00 10 01 01 10 11 10 00 01 00 10 00 10 00 10 00 01 10 11 00 10 00 01 11 00 00 10 01 11 10 10 10 10 00 10 00 10 10 00 10 01 11 11 01 00 10 01 00 11 01 11 00 00 11 10 01 01 11 00 10 11 00 11 00 11 01 10 01 00 10 10 11 10 10 01 11 10 10 00 11 00 00 01 00 10 00 10 00 10 01 00 10 01 11 10 00 10 00 10 11 00 00 10 10 11 10 01 01 00 11 00 10 00 10 00 01 01 01 00 10 00 10 00 10 00 10 00 11 11 11 11 10 10 00 00 10 00 10 10 01 00 10 00 10 00 10 01 00 10 00 10 01 01 01 10 11 11 01 01 00 10 00 10 00 01 00 01 11 00 10 01 00 10 00 10 00 10 01 00 01 10 10
и вот ещё PDU фрейм: (там должна быть информация SysID или WACN ID, Site, RX и TX каналы этого УК (2-3310 (460.ххх мгц) и 2-1620 (450.125 мгц)) и что-то ещё.
//преамбула
01 01 01 01 01 11 01 01 11 11 01 01 11 11 11 11 01 11 01 11 11 11 11 11
//содержимое
00 10 11 00 00 01 11 00 00 10 00 10 11 01 00 10 10 10 01 10 01 10 11 10 01 10 00 00 10 01 10 01 10 00 10 10 00 11 10 00 10 00 10 01 00 10 10 10 11 10 10 01 00 10 11 00 10 00 01 01 11 11 10 00 00 10 00 10 11 00 01 01 10 01 11 11 00 10 00 10 11 10 10 10 11 10 11 10 00 00 10 00 10 11 10 00 10 00 10 01 10 00 10 00 10 00 01 11 10 00 11 10 11 00 10 00 10 00 01 11 00 01 11 00 10 10 00 10 00 10 01 00 11 11 00 10 11 10 11 10 01 11 00 10 11 11 01 11 00 10 11 11 00 00 10 10 11 11 10 11 10 00 10 00 10 00 01 00 00 00 01 01 10 00 11 00 10 01 01 11 01 11 10 11 11 00 10 00 10 01 11 10 00 00 01 00 01 00 01 01 00 10 00 01 10 10 11 11 01 01 11 00 11 00 11 01 11 10 01 01 01 10 00 10 00 10 01 10 11 01 00 10 11 11 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 10
|
|
|
Дата: 10 Апр 2021 21:30:45
#
killer258
[i]Плюс, была произведена коррекция частоты манипуляции. А это как? можно подробнее?[/i]
Corr_Br - это из инструментария SA. Если коротко, то - вычисляется истинная частота манипуляции (разными методами,
от взятия огибающей, автоматического определения Br и до ручной коррекции уровней в демодуляторе). Далее, программа высчитывает коэффициент поправки относительно фактического Br и априори известного и, в данном случае я
синтезировал файл rrc_02_corr_br.wav уже с учетом этой поправки.
|
|
|
Дата: 10 Апр 2021 21:43:53
#
для сравнения дайте , если не трудно, тот же файл, но теперь без этой поправки. Хочу посмотреть, на чём это отразится при декодировании, насколько хуже будет ситуация с ошибками
|
|
|
Дата: 10 Апр 2021 23:29:35 · Поправил: killer258 (11 Апр 2021 21:25:42)
#
разбил первый TSBK на микрослоты (статусные биты торчат сбоку после каждого 35-го дибита) :
01 01 01 01 01 11 01 (начало с преамбулы +3+3+3+3+3... )
01 11 11 01 01 11 11
11 11 01 11 01 11 11
11 11 11 00 10 11 00
00 01 01 11 00 00 11 10
01 11 00 01 00 01 10
11 01 00 11 10 01 10
01 11 11 11 01 10 00
00 10 00 10 11 00 11
10 00 10 00 10 10 01 10
00 11 10 01 01 00 11
00 11 11 01 01 11 11
00 10 11 10 11 00 00
10 11 11 00 10 01 10
11 00 10 00 11 01 01 10
10 10 11 00 10 11 00
11 10 00 10 01 01 00
10 10 10 11 10 10 00
01 11 01 00 11 10 00
10 00 00 00 10 00 10 11
00 01 11 00 10 10 00
01 01 01 11 10 10 00
00 10 11 01 00 10 00
10 00 10 00 10 00 10
00 10 00 10 00 10 11 10
11 00 11 01 01 00 10
01 11 00 10 00 10 00
10 00 10 00 10 00 10
00 10 00 10 10 11 01
01 11 00 11 10 00 10 10
00 10 00 10 00 10 00
10 00 10 00 10 00 10
11 10 00 10 00 00 00
10 00 10 00 10 00 10
00 10 00 10 00 10 00 10
10 00 10 11 00 11 11
00 01 00 10 00 10 11
10 00 10 00 10 10 01
11 10 01 00 10 01 00
01 11 01 10 01 01 00 10
00 10 00 01 11 00 00
10 11 11 00 10 11 11
01 01 00 10 10 01 01
00 10 11 00 10 01 11
11 10 00 10 01 01 11 10
00 10 00 11 00 00 10
00 01 10 11 11 10 00
10 00 00 00 10 00 10
00 01 00 00 01 10 11
01 00 10 01 11 11 01 11
итого, микрослотов десять.
|
|
|
Дата: 10 Апр 2021 23:41:15
#
теперь надо бы понять, с какой из двух модификаций я имею дело. Вся беда в том, что их две:
вот такая
Увеличить
и вот такая: 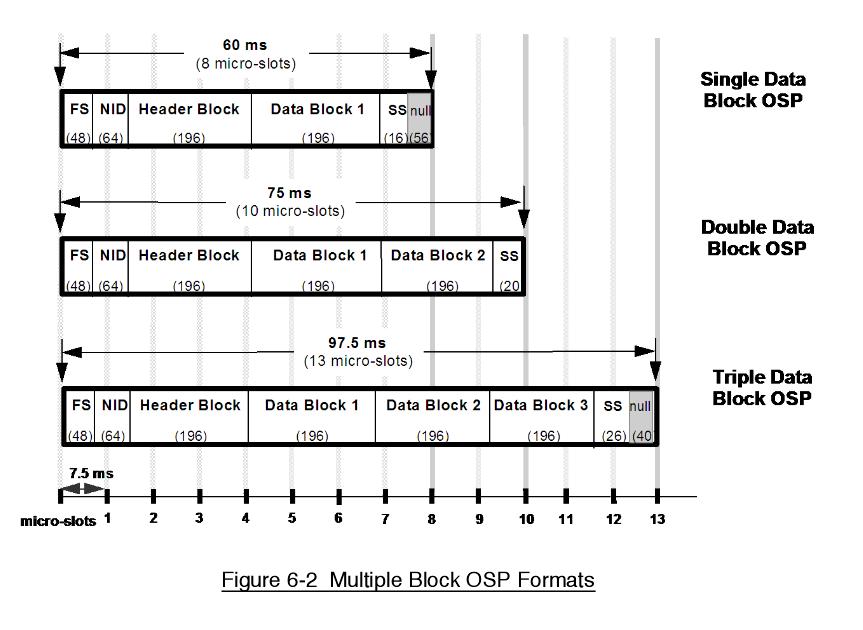
Увеличить
и в той, и в той есть вариант с 10 слотами. Предполагаю, что всё-таки имею дело с первой, потому что по описанию вторая применяется реже. |
|
|
Дата: 10 Апр 2021 23:54:32 · Поправил: killer258 (11 Апр 2021 09:59:22)
#
если я имею дело с первой модификацией, то тогда переые 12 октетов, идущие после NID,
нужно интерпретировать как вот это
Увеличить
а если со второй модификацией, то тогда первые 12 октетов это неader block, и интерпретировать его надо уже тогда как вот это:
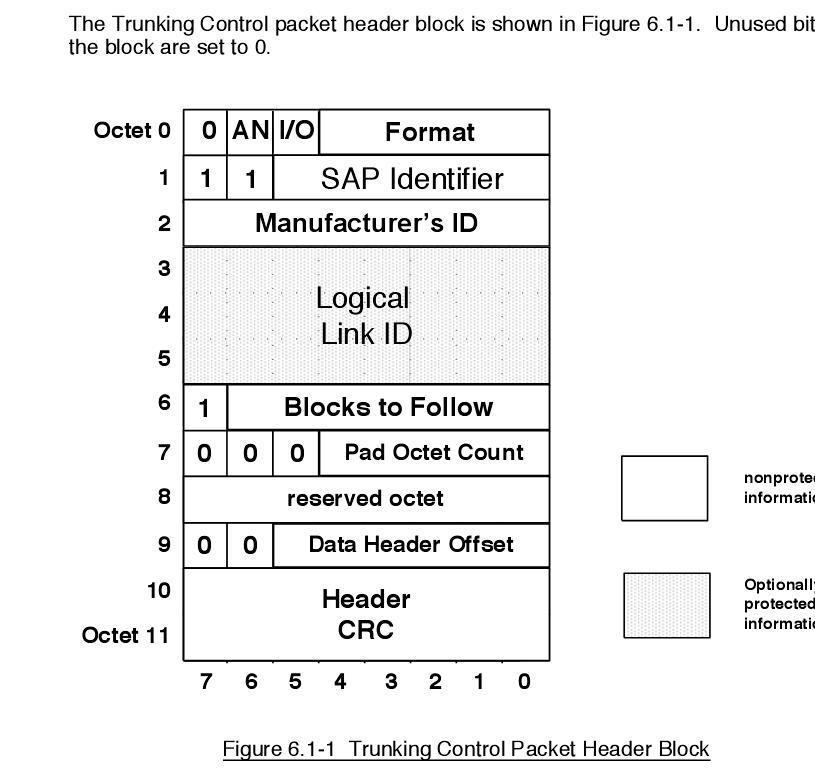
Увеличить
Интересно, а как же прошивка приёмного оборудования отличает , с какой модификацией она сталкивается при приёме фрейма? И там, и там 12 октетов, только поля означают разное по смыслу. Не, ну должен же быть какой-то отличительный признак, ну там бит какой-то где-нибудь или ещё как-то |
|
|
Дата: 11 Апр 2021 00:02:15 · Поправил: killer258 (11 Апр 2021 10:00:08)
#
для начала надо бы найти первые 12 октетов. Они начинаются сразу после NID, который содержит 64 бит и идёт сразу после преамбулы. Он состоит из 12 бит NAC,4 битов DUID, и проверочных данных БЧХ, в сумме 64 бита (интересно, это с учётом статусных или без учета? Или реально всё-таки надо отступить 66 бит от конца преамбулы? иначе можно , отыскивая начало первого октета, ошибиться с месторасположением начала первого октета на 2 бита.
Или придётся проверять оба предположения.
Пусть будет для начала 66 бит. (12 Nac+4 DUID +48 BCH +2 статусных =66 )
Надо пропустить 66 бит (33 дибита) после конца преамбулы.
|
|
|
Дата: 11 Апр 2021 00:32:35 · Поправил: killer258 (11 Апр 2021 10:08:12)
#
пропустив первые 33 дибита после конца преамбулы,(то бишь NID вместе с БЧХ битами и один затесавшийся туда статусный дибит) имеем без статусных:
00 10 00 10 11 00 11 10
00 10 00 10 10 01 00 11
10 01 01 00 11 00 11 11
01 01 11 11 00 10 11 10
11 00 00 10 11 11 00 10
01 10 11 00 10 00 11 01
01 10 10 11 00 10 11 00
11 10 00 10 01 01 00 10
10 10 11 10 10 00 01 11
01 00 11 10 00 10 00 00
00 10 00 10 00 01 11 00
10 10 00 01 01 01 11 10
10 00 00 10 11 01 00 10
00 10 00 10 00 10 00 10
00 10 00 10 00 10 11 11
00 11 01 01 00 10 01 11
00 10 00 10 00 10 00 10
00 10 00 10 00 10 00 10
10 11 01 01 11 00 11 10
00 10 00 10 00 10 00 10
00 10 00 10 00 10 00 10
11 10 00 10 00 00 00 10
00 10 00 10 00 10 00 10
00 10 00 10 00 10 00 10
11 00 11 11 00 01 00 10
00 10 11 10 00 10 00 10
10 01 11 10 01 00 10 01
00 01 11 01 10 01 01 00
00 10 00 01 11 00 00 10
11 11 00 10 11 11 01 01
00 10 10 01 01 00 10 11
00 10 01 11 11 10 00 10
01 01 11 00 10 00 11 00
00 10 00 01 10 11 11 10
00 10 00 00 00 10 00 10
00 01 00 00 01 10 11 01
00 10 01 11 11 01
вроде как три блока, но- они не по 96 бит (12 октетов это 12х8=96), а по 192 бита... Непонятно, как их тогда интерпретировать.
и cамая последняя неполная строчка видимо тот самый таинственный SS без Null битов:-) ?
|
|
|
Дата: 11 Апр 2021 01:21:17 · Поправил: killer258 (11 Апр 2021 10:08:36)
#
в описании вскользь упоминается, что Packet structure :
Each control channel message is considered a packet. Each packet is
composed of one or more information blocks. Each block is protected by a rate
1/2 trellis code, and the sequence of blocks is transferred over the common air
interface as a single packet.
но дальше об этом "by a rate 1/2 trellis code" нигде ни слова. А я предполагаю, что именно в этом всё и дело, поэтому у меня opcode не совпадает ни с одним допустимым и размер не тот.
Интересно, как тут использован этот треллис? Без этого дальше не продвинуться.
|